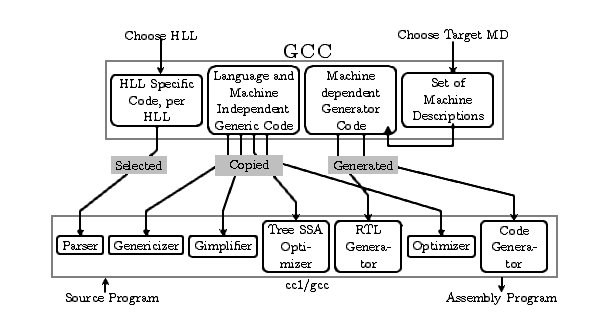
Figure 1.1: The GCC Compiler Generation Framework (CGF).
The volume of detail in GCC is rather large. This is one place where all the detail information about the GCC files, their logical organization and such other details are collected together. This document serves as a reference to detail of the conceptual layers described in the other documents. In a sense it is a collection of the “appendices” of the other documents.
In this document we note the details of the GCC 4.0.2 implementation given the background of the architecture described in The Conceptual Structure of GCC, and the corresponding implementation described in The Implementation of GCC. The “Compiler Generation Framework” figure that appears below succinctly captures the core concepts in GCC. We also take support from the GCC Internals documentation (see GCC Internals (by Richard Stallman)) available for a few versions of GCC which describe in detail the uses of various macros and RTL objects in detail. The source layout structure described in GCC – An Introduction is used.
The various details follow. Some more details can also be added as reference in the future. For instance, systematic grouping and description of accessor macros that are used to access and manipulate internal data structures like the AST/Generic trees, RTL objects and details of target characteristics etc. can be added here. In some cases, the description has been derived from the comments in the source files themselves.
The pristine sources of GCC are downloadable from any official GCC
distribution site on the Internet. The list of sites is available on
the official GCC site. A gzipped tape
archive for GCC version 4.1.2 is named as gcc-4.1.2.tar.gz.
These sources are extracted in a directory that we denote by
$GCCHOME. Conventionally, the sources extract into a set of
directories and files in a directory named gcc-x.y.z, where
x, y and z are version digits. For example the
GCC version 4.1.2 sources extract into a directory named
gcc-4.1.2. Thus gcc-x.y.z is (usually) the last
directory component of $GCCHOME. This description of the GCC
source organization strives to build the intuition behind the
structure that one obtains on unpacking the distribution. We emphasize
that this is GCC specific, and some variations are possible in
principle.
The HLL specific components, the target back end components and the actual compiler logic are separate. A driver is needed to collect the components for the chosen HLL and target pair, and “assemble” the final compiler sources which are subsequently compiled. This strategy allows creating various kinds of compilers like native, cross or Canadian cross.
The source and target independent parts of the compiler are within the
$GCCHOME/gcc subdirectory of the main source trunk.
It is in this directory that we find the code that
Corresponding to each HLL, except C1, is a directory within
$GCCHOME/gcc which all the code for processing that language
exists. In particular this involves scanning the tokens of that
language and creating the ASTs. If necessary, the basic AST tree node
types need to be augmented with variations for this language. The
main compiler calls these routines to handle input of that language.
To isolate itself from the details of the source language, the main
compiler uses a table of function pointers that are to be used to
perform each required task. A language implementation needs to fill
in such data structures of the main compiler code and build the
language specific processing chain until the AST is obtained.
The back end specific code is organized as a list of directories
corresponding to each supported back end system. This list of
supported back ends is separately housed in $GCCHOME/gcc/config
directory of the main trunk.
Parts of the compiler that are common and find frequent usage have
also been separated into a separate library called the
libiberty and placed in a distinct subdirectory of
$GCCHOME. This facilitates a one-time build of these common
routines. We emphasize that these routines are common to the main
compiler, the front end code and the back end code (e.g. regular
expressions handling); the routines common to only the main compiler
still reside in the main compiler directory, i.e. $GCCHOME/gcc.
GCC also implements a garbage collection based memory management
system for it's use during a run. This code is placed in the
subdirectory $GCCHOME/boehm-gc.
We focus on files relevant to understanding the compiler. Hence files
like Changelogs, READMEs, COPYING, FAQ and
such have been omitted below.
GCC uses internal garbage collection to manage it's own memory during a run. Supporting each front end may require additional libraries which are also bundled with the GCC sources, except the C library which is a separate package. A few other directories have code for different purposes like maintenance, description of the building and installation procedure etc. Here is a summary.
$GCCHOME/boehm-gc
| Garbage collector
|
$GCCHOME/config
| Collection of system specific flags
|
$GCCHOME/contrib
| Useful contributed code
|
$GCCHOME/fastjar
| Bundled Java archiver
|
$GCCHOME/INSTALL
| Install instructions
|
$GCCHOME/libf2c
| Fortran-to-C library
|
$GCCHOME/libffi
| Bundled Foreign Function Interface
|
$GCCHOME/libiberty
| Common GNU routines library
|
$GCCHOME/libjava
| Java library
|
$GCCHOME/libobjc
| Objective C library
|
$GCCHOME/libstdc++-v3
| C++ Library
|
$GCCHOME/maintainer-scripts
| Scripts used by maintainers
|
$GCCHOME/zlib
| General purpose compression library
|
Apart from the directory organization, $GCCHOME also has code
and data to build and install the sources. GCC uses autoconf
generated configure script to obtain the detailed building
requirements. This script is supported by a few other scripts. It
emits the top level Makefile using a few data files in
$GCCHOME. The make command that uses this
Makefile also needs some supporting scripts which reside here.
These scripts thus are used in various phases: configuration,
building, and installation of the compiler.
$GCCHOME/install-sh
| $GCCHOME/libtool.m4
|
$GCCHOME/ltcf-c.sh
| $GCCHOME/ltcf-cxx.sh
|
$GCCHOME/ltcf-gcj.sh
| $GCCHOME/ltconfig
|
$GCCHOME/ltmain.sh
| $GCCHOME/Makefile.def
|
$GCCHOME/Makefile.in
| $GCCHOME/Makefile.tpl
|
$GCCHOME/missing
| $GCCHOME/mkdep
|
$GCCHOME/mkinstalldirs
| $GCCHOME/move-if-change
|
$GCCHOME/shmake
| $GCCHOME/symlink-tree
|
$GCCHOME/ylwrap
| $GCCHOME/config.guess
|
$GCCHOME/config.if
| $GCCHOME/config.sub
|
$GCCHOME/configure
| $GCCHOME/configure.in
|
$GCCHOME/config-ml.in
|
|
configure uses the config.guess script to guess the
canonical name when the user has not supplied one. The canonical name
of a system – build, host or target – is made up of a triple, or
some times a quadruple of CPU type (sparc), Manufacturer (sun),
operating system (unix), and sometimes the kernel (linux) as the third
of the quadruple. The config.sub script is used to validate a
given canonical name, i.e. it checks if the given name is supported or
not. Adding a new backend may involve adding some code the
config.sub to recognize the new target.
The main compiler sources reside in $GCCHOME/gcc directory.
This directory contains five categories of code: the supported front
ends, the supported back ends, auxiliary code for various purposes
like internationalization support, hacks to fix vendor supplied files,
the test suite etc., the include files, and the main compiler sources.
Here are the various directories and files.
This code deals with processing the program as expressed by the user and corresponds to the “Language Specific Code” part of GCC box in Fig.(the GCC compiler generation framework figure).
$GCCHOME/gcc/f
| Fortran front end
|
$GCCHOME/gcc/ada
| Ada front end
|
$GCCHOME/gcc/cp
| C++ front end
|
$GCCHOME/gcc/java
| Java front end
|
$GCCHOME/gcc/objc
| Objective C front end
|
$GCCHOME/gcc/treelang
| Treelang front end
|
The back end support code resides in the $GCCHOME/gcc/config
directory and corresponds to the “Machine Dependent Generator Code”
part of the GCC box in Fig.(the GCC compiler generation framework figure). The specifications of supported target are found in
individual subdirectories and are the input to the generation
mechanism (files in section gen:srcs) that generates the target
specific information for the compiler in the bottom half of
Fig.(the GCC compiler generation framework figure). This
directory contains two main types of files. The common header files
usually contain code for various target systems and reside in
$GCCHOME/gcc/config (referred to as $BACKEND below)
itself while the actual target machine description files are found in
respective subdirectories.
Back end common files
$BACKEND/aoutos.h
| $BACKEND/chorus.h
|
$BACKEND/darwin-c.c
| $BACKEND/darwin-crt2.c
|
$BACKEND/darwin-protos.h
| $BACKEND/darwin.c
|
$BACKEND/darwin.h
| $BACKEND/dbx.h
|
$BACKEND/dbxcoff.h
| $BACKEND/dbxelf.h
|
$BACKEND/divmod.c
| $BACKEND/elfos.h
|
$BACKEND/fp-bit.c
| $BACKEND/fp-bit.h
|
$BACKEND/freebsd-nthr.h
| $BACKEND/freebsd-spec.h
|
$BACKEND/freebsd.h
| $BACKEND/freebsd3.h
|
$BACKEND/freebsd4.h
| $BACKEND/freebsd5.h
|
$BACKEND/freebsd6.h
| $BACKEND/gnu.h
|
$BACKEND/gofast.h
| $BACKEND/interix.h
|
$BACKEND/interix3.h
| $BACKEND/libgcc-glibc.ver
|
$BACKEND/libgloss.h
| $BACKEND/linux-aout.h
|
$BACKEND/linux.h
| $BACKEND/lynx-ng.h
|
$BACKEND/lynx.h
| $BACKEND/netbsd-aout.h
|
$BACKEND/netbsd-elf.h
| $BACKEND/netbsd.h
|
$BACKEND/netware.h
| $BACKEND/openbsd-oldgas.h
|
$BACKEND/openbsd.h
| $BACKEND/psos.h
|
$BACKEND/ptx4.h
| $BACKEND/rtems.h
|
$BACKEND/sol2.h
| $BACKEND/svr3.h
|
$BACKEND/svr4.h
| $BACKEND/t-darwin
|
$BACKEND/t-freebsd
| $BACKEND/t-freebsd-thread
|
$BACKEND/t-gnu
| $BACKEND/t-interix
|
$BACKEND/t-libc-ok
| $BACKEND/t-libgcc-pic
|
$BACKEND/t-libunwind
| $BACKEND/t-linux
|
$BACKEND/t-linux-aout
| $BACKEND/t-linux-gnulibc1
|
$BACKEND/t-netbsd
| $BACKEND/t-openbsd
|
$BACKEND/t-rtems
| $BACKEND/t-slibgcc-sld
|
$BACKEND/t-svr4
| $BACKEND/tm-dwarf2.h
|
$BACKEND/udivmod.c
| $BACKEND/udivmodsi4.c
|
$BACKEND/usegas.h
| $BACKEND/x-interix
|
$BACKEND/t-openbsd-thread
| $BACKEND/t-slibgcc-elf-ver
|
$BACKEND/t-slibgcc-nolc-override
|
|
Back end machine description
For each of the supported back end targets, GCC uses the following layout:
$BACKEND/<target-directory>
|
|
$BACKEND/<target-directory>/<target>.h
|
|
$BACKEND/<target-directory>/<target>.md
|
|
$BACKEND/<target-directory>/<target>.c
|
|
$BACKEND/<target-directory>/<other files>
|
|
The following directories contain auxiliary files as follows:
$GCCHOME/gcc/doc
| Documentation in texinfo format
|
$GCCHOME/gcc/fixinc
| Hacks to fix vendor's include files
|
$GCCHOME/gcc/ginclude
| Additional includes for ISO C support
|
$GCCHOME/gcc/intl
| GCC Internationalization support
|
$GCCHOME/gcc/po
| Internationalization data strings
|
$GCCHOME/gcc/testsuite
| GCC test suite
|
The common include files of the compiler reside in the
$GCCHOME/include directory. This is referred to below as
$GCCINCLUDES.
$GCCINCLUDES/ansidecl.h
| $GCCINCLUDES/demangle.h
|
$GCCINCLUDES/dyn-string.h
| $GCCINCLUDES/fibheap.h
|
$GCCINCLUDES/floatformat.h
| $GCCINCLUDES/fnmatch.h
|
$GCCINCLUDES/getopt.h
| $GCCINCLUDES/hashtab.h
|
$GCCINCLUDES/libiberty.h
| $GCCINCLUDES/md5.h
|
$GCCINCLUDES/objalloc.h
| $GCCINCLUDES/obstack.h
|
$GCCINCLUDES/partition.h
| $GCCINCLUDES/safe-ctype.h
|
$GCCINCLUDES/sort.h
| $GCCINCLUDES/splay-tree.h
|
$GCCINCLUDES/symcat.h
| $GCCINCLUDES/ternary.h
|
$GCCINCLUDES/xregex.h
| $GCCINCLUDES/xregex2.h
|
The bulk of the sources reside in the $GCCHOME/gcc directory.
We will refer to this directory as $MAINSRCS below. We divide
the sources into the following six types: scripts, templates to drive
the scripts, definitions, C sources that are used to generate sources
with target specific information at build time, C include files and C
sources.
$MAINSRCS/configure
| $MAINSRCS/fixproto
|
$MAINSRCS/genmultilib
| $MAINSRCS/mkinstalldirs
|
$MAINSRCS/move-if-change
| $MAINSRCS/sort-protos
|
$MAINSRCS/mkmap-flat.awk
| $MAINSRCS/mkmap-symver.awk
|
$MAINSRCS/configure.frag
| $MAINSRCS/config.gcc
|
$MAINSRCS/config.guess
| $MAINSRCS/aclocal.m4
|
$MAINSRCS/mkconfig.sh
| $MAINSRCS/scan-types.sh
|
$MAINSRCS/c-config-lang.in
| $MAINSRCS/config.in
|
$MAINSRCS/configure.in
| $MAINSRCS/c-parse.in
|
$MAINSRCS/cstamp-h.in
| $MAINSRCS/gccbug.in
|
$MAINSRCS/gdbinit.in
| $MAINSRCS/Makefile.in
|
$MAINSRCS/mkheaders.in
| $MAINSRCS/mklibgcc.in
|
Of particular interest for the study of the GCC compiler are the
tree.def, c-common.def, rtl.def and
machmode.def definition files. tree.def and
c-co-mmon.def together define all the AST node types.
rtl.def defines all the various RTL types that a given version
GCC uses internally. Finally, the machmode.def file defines
the RTL Abstract machine data types with their relative size in bytes.
$MAINSRCS/builtin-attrs.def
| $MAINSRCS/builtins.def
|
$MAINSRCS/builtin-types.def
| $MAINSRCS/c-common.def
|
$MAINSRCS/diagnostic.def
| $MAINSRCS/machmode.def
|
$MAINSRCS/params.def
| $MAINSRCS/predict.def
|
$MAINSRCS/rtl.def
| $MAINSRCS/stab.def
|
$MAINSRCS/timevar.def
| $MAINSRCS/tree.def
|
$MAINSRCS/genattrtab.h
| $MAINSRCS/gengtype.h
|
$MAINSRCS/gengtype-yacc.h
| $MAINSRCS/gensupport.h
|
Sources
$MAINSRCS/genattr.c
| $MAINSRCS/genattrtab.c
|
$MAINSRCS/genautomata.c
| $MAINSRCS/gencheck.c
|
$MAINSRCS/gencodes.c
| $MAINSRCS/genconditions.c
|
$MAINSRCS/genconfig.c
| $MAINSRCS/genconstants.c
|
$MAINSRCS/genemit.c
| $MAINSRCS/genextract.c
|
$MAINSRCS/genflags.c
| $MAINSRCS/gengenrtl.c
|
$MAINSRCS/gengtype.c
| $MAINSRCS/gengtype-lex.c
|
$MAINSRCS/gengtype-yacc.c
| $MAINSRCS/genopinit.c
|
$MAINSRCS/genoutput.c
| $MAINSRCS/genpeep.c
|
$MAINSRCS/genpreds.c
| $MAINSRCS/gen-protos.c
|
$MAINSRCS/genrecog.c
| $MAINSRCS/gensupport.c
|
$MAINSRCS/acconfig.h
| $MAINSRCS/basic-block.h
|
$MAINSRCS/bitmap.h
| $MAINSRCS/c-common.h
|
$MAINSRCS/cfglayout.h
| $MAINSRCS/collect2.h
|
$MAINSRCS/conditions.h
| $MAINSRCS/convert.h
|
$MAINSRCS/cppdefault.h
| $MAINSRCS/cpphash.h
|
$MAINSRCS/cpplib.h
| $MAINSRCS/c-pragma.h
|
$MAINSRCS/c-pretty-print.h
| $MAINSRCS/cselib.h
|
$MAINSRCS/c-tree.h
| $MAINSRCS/dbxout.h
|
$MAINSRCS/dbxstclass.h
| $MAINSRCS/debug.h
|
$MAINSRCS/defaults.h
| $MAINSRCS/df.h
|
$MAINSRCS/diagnostic.h
| $MAINSRCS/dwarf2asm.h
|
$MAINSRCS/dwarf2.h
| $MAINSRCS/dwarf2out.h
|
$MAINSRCS/dwarf.h
| $MAINSRCS/errors.h
|
$MAINSRCS/et-forest.h
| $MAINSRCS/except.h
|
$MAINSRCS/expr.h
| $MAINSRCS/flags.h
|
$MAINSRCS/function.h
| $MAINSRCS/gbl-ctors.h
|
$MAINSRCS/gcc.h
| $MAINSRCS/gcov-io.h
|
$MAINSRCS/ggc.h
| $MAINSRCS/glimits.h
|
$MAINSRCS/graph.h
| $MAINSRCS/gstab.h
|
$MAINSRCS/gsyms.h
| $MAINSRCS/gsyslimits.h
|
$MAINSRCS/gthr-aix.h
| $MAINSRCS/gthr-dce.h
|
$MAINSRCS/gthr.h
| $MAINSRCS/gthr-posix.h
|
$MAINSRCS/gthr-rtems.h
| $MAINSRCS/gthr-single.h
|
$MAINSRCS/gthr-solaris.h
| $MAINSRCS/gthr-vxworks.h
|
$MAINSRCS/gthr-win32.h
| $MAINSRCS/hard-reg-set.h
|
$MAINSRCS/hashtable.h
| $MAINSRCS/hooks.h
|
$MAINSRCS/hwint.h
| $MAINSRCS/input.h
|
$MAINSRCS/insn-addr.h
| $MAINSRCS/integrate.h
|
$MAINSRCS/intl.h
| $MAINSRCS/langhooks-def.h
|
$MAINSRCS/langhooks.h
| $MAINSRCS/libfuncs.h
|
$MAINSRCS/libgcc2.h
| $MAINSRCS/limitx.h
|
$MAINSRCS/limity.h
| $MAINSRCS/line-map.h
|
$MAINSRCS/location.h
| $MAINSRCS/longlong.h
|
$MAINSRCS/loop.h
| $MAINSRCS/machmode.h
|
$MAINSRCS/mbchar.h
| $MAINSRCS/mkdeps.h
|
$MAINSRCS/optabs.h
| $MAINSRCS/output.h
|
$MAINSRCS/params.h
| $MAINSRCS/predict.h
|
$MAINSRCS/prefix.h
| $MAINSRCS/pretty-print.h
|
$MAINSRCS/profile.h
| $MAINSRCS/ra.h
|
$MAINSRCS/real.h
| $MAINSRCS/recog.h
|
$MAINSRCS/regs.h
| $MAINSRCS/reload.h
|
$MAINSRCS/resource.h
| $MAINSRCS/rtl.h
|
$MAINSRCS/sbitmap.h
| $MAINSRCS/scan.h
|
$MAINSRCS/sched-int.h
| $MAINSRCS/sdbout.h
|
$MAINSRCS/ssa.h
| $MAINSRCS/stack.h
|
$MAINSRCS/sys-protos.h
| $MAINSRCS/system.h
|
$MAINSRCS/sys-types.h
| $MAINSRCS/target-def.h
|
$MAINSRCS/target.h
| $MAINSRCS/timevar.h
|
$MAINSRCS/toplev.h
| $MAINSRCS/tree-dump.h
|
$MAINSRCS/tree.h
| $MAINSRCS/tree-inline.h
|
$MAINSRCS/tsystem.h
| $MAINSRCS/typeclass.h
|
$MAINSRCS/unwind-dw2-fde.h
| $MAINSRCS/unwind.h
|
$MAINSRCS/unwind-pe.h
| $MAINSRCS/varray.h
|
$MAINSRCS/version.h
| $MAINSRCS/vmsdbg.h
|
$MAINSRCS/xcoffout.h
| $MAINSRCS/unwind.inc
|
We further divide the sources depending on the concept being
implemented by them as: front end processing, Interfacing with the
rest of the compiler, main compilation phases, optimizations, tools
chain interfacing, C preprocessing, measurements and diagnostics,
error detection and reporting, debugging, the gcc driver files
and other miscellaneous files. These divisions, however, are rough
since a source file sometimes contains code that is useful in a
different context too.
Front end processing
$MAINSRCS/attribs.c
| $MAINSRCS/c-aux-info.c
|
$MAINSRCS/c-common.c
| $MAINSRCS/c-convert.c
|
$MAINSRCS/c-decl.c
| $MAINSRCS/c-dump.c
|
$MAINSRCS/c-errors.c
| $MAINSRCS/c-format.c
|
$MAINSRCS/c-lang.c
| $MAINSRCS/c-lex.c
|
$MAINSRCS/c-objc-common.c
| $MAINSRCS/c-opts.c
|
$MAINSRCS/c-parse.c
| $MAINSRCS/c-semantics.c
|
$MAINSRCS/c-typeck.c
| $MAINSRCS/langhooks.c
|
$MAINSRCS/bitmap.c
| $MAINSRCS/builtins.c
|
$MAINSRCS/fix-header.c
| $MAINSRCS/ggc-common.c
|
$MAINSRCS/ggc-none.c
| $MAINSRCS/ggc-page.c
|
$MAINSRCS/ggc-simple.c
| $MAINSRCS/sbitmap.c
|
$MAINSRCS/stringpool.c
|
|
$MAINSRCS/caller-save.c
| $MAINSRCS/calls.c
|
$MAINSRCS/conflict.c
| $MAINSRCS/convert.c
|
$MAINSRCS/dummy-conditions.c
| $MAINSRCS/emit-rtl.c
|
$MAINSRCS/et-forest.c
| $MAINSRCS/explow.c
|
$MAINSRCS/expmed.c
| $MAINSRCS/expr.c
|
$MAINSRCS/final.c
| $MAINSRCS/floatlib.c
|
$MAINSRCS/fp-test.c
| $MAINSRCS/function.c
|
$MAINSRCS/gcov.c
| $MAINSRCS/global.c
|
$MAINSRCS/haifa-sched.c
| $MAINSRCS/hashtable.c
|
$MAINSRCS/hooks.c
| $MAINSRCS/ifcvt.c
|
$MAINSRCS/integrate.c
| $MAINSRCS/line-map.c
|
$MAINSRCS/lists.c
| $MAINSRCS/local-alloc.c
|
$MAINSRCS/main.c
| $MAINSRCS/optabs.c
|
$MAINSRCS/params.c
| $MAINSRCS/predict.c
|
$MAINSRCS/profile.c
| $MAINSRCS/protoize.c
|
$MAINSRCS/ra-build.c
| $MAINSRCS/ra.c
|
$MAINSRCS/ra-colorize.c
| $MAINSRCS/ra-rewrite.c
|
$MAINSRCS/read-rtl.c
| $MAINSRCS/real.c
|
$MAINSRCS/recog.c
| $MAINSRCS/regclass.c
|
$MAINSRCS/regmove.c
| $MAINSRCS/regrename.c
|
$MAINSRCS/reg-stack.c
| $MAINSRCS/reload1.c
|
$MAINSRCS/reload.c
| $MAINSRCS/reorg.c
|
$MAINSRCS/resource.c
| $MAINSRCS/rtlanal.c
|
$MAINSRCS/rtl.c
| $MAINSRCS/sched-deps.c
|
$MAINSRCS/sched-ebb.c
| $MAINSRCS/sched-rgn.c
|
$MAINSRCS/sched-vis.c
| $MAINSRCS/simplify-rtx.c
|
$MAINSRCS/ssa.c
| $MAINSRCS/stmt.c
|
$MAINSRCS/stor-layout.c
| $MAINSRCS/toplev.c
|
$MAINSRCS/tracer.c
| $MAINSRCS/tree.c
|
$MAINSRCS/tree-inline.c
| $MAINSRCS/varray.c
|
$MAINSRCS/version.c
| $MAINSRCS/gengtype-lex.l
|
$MAINSRCS/c-parse.y
| $MAINSRCS/gengtype-yacc.y
|
$MAINSRCS/libgcc-std.ver
|
|
$MAINSRCS/alias.c
| $MAINSRCS/bb-reorder.c
|
$MAINSRCS/cfganal.c
| $MAINSRCS/cfgbuild.c
|
$MAINSRCS/cfg.c
| $MAINSRCS/cfgcleanup.c
|
$MAINSRCS/cfglayout.c
| $MAINSRCS/cfgloop.c
|
$MAINSRCS/cfgrtl.c
| $MAINSRCS/combine.c
|
$MAINSRCS/cse.c
| $MAINSRCS/cselib.c
|
$MAINSRCS/df.c
| $MAINSRCS/doloop.c
|
$MAINSRCS/dominance.c
| $MAINSRCS/flow.c
|
$MAINSRCS/fold-const.c
| $MAINSRCS/gcse.c
|
$MAINSRCS/jump.c
| $MAINSRCS/lcm.c
|
$MAINSRCS/loop.c
| $MAINSRCS/sibcall.c
|
$MAINSRCS/ssa-ccp.c
| $MAINSRCS/ssa-dce.c
|
$MAINSRCS/unroll.c
|
|
$MAINSRCS/collect2.c
| $MAINSRCS/c-pretty-print.c
|
$MAINSRCS/crtstuff.c
| $MAINSRCS/graph.c
|
$MAINSRCS/intl.c
| $MAINSRCS/libgcc2.c
|
$MAINSRCS/mbchar.c
| $MAINSRCS/prefix.c
|
$MAINSRCS/tlink.c
| $MAINSRCS/varasm.c
|
$MAINSRCS/xcoffout.c
|
|
$MAINSRCS/cppdefault.c
| $MAINSRCS/cpperror.c
|
$MAINSRCS/cppexp.c
| $MAINSRCS/cppfiles.c
|
$MAINSRCS/cpphash.c
| $MAINSRCS/cppinit.c
|
$MAINSRCS/cpplex.c
| $MAINSRCS/cpplib.c
|
$MAINSRCS/cppmacro.c
| $MAINSRCS/cppmain.c
|
$MAINSRCS/cppspec.c
| $MAINSRCS/cpptrad.c
|
$MAINSRCS/c-pragma.c
| $MAINSRCS/scan.c
|
$MAINSRCS/scan-decls.c
|
|
$MAINSRCS/diagnostic.c
| $MAINSRCS/gmon.c
|
$MAINSRCS/timevar.c
|
|
$MAINSRCS/doschk.c
| $MAINSRCS/errors.c
|
$MAINSRCS/except.c
| $MAINSRCS/rtl-error.c
|
$MAINSRCS/unwind-c.c
| $MAINSRCS/unwind-dw2.c
|
$MAINSRCS/unwind-dw2-fde.c
| $MAINSRCS/unwind-dw2-fde-darwin.c
|
$MAINSRCS/unwind-dw2-fde-glibc.c
| $MAINSRCS/unwind-libunwind.c
|
$MAINSRCS/unwind-sjlj.c
|
|
$MAINSRCS/dbxout.c
| $MAINSRCS/debug.c
|
$MAINSRCS/dwarf2asm.c
| $MAINSRCS/dwarf2out.c
|
$MAINSRCS/dwarfout.c
| $MAINSRCS/print-rtl1.c
|
$MAINSRCS/print-rtl.c
| $MAINSRCS/print-tree.c
|
$MAINSRCS/ra-debug.c
| $MAINSRCS/sdbout.c
|
$MAINSRCS/tree-dump.c
| $MAINSRCS/vmsdbgout.c
|
gcc driver files
$MAINSRCS/gcc.c
| $MAINSRCS/gccspec.c
|
$MAINSRCS/mips-tdump.c
| $MAINSRCS/mips-tfile.c
|
$MAINSRCS/mkdeps.c
|
|
This section summarises a few “generator” programs that process the information in the selected MD at tbuild. Most of the synopses and descriptions are extracted from the commentary in the source files themselves. These form the first of the details of the target specific code generation activity at build time. The main goal is to generate the target specific RTL part of the Gimple –> translation table (see The Implementation of GCC, The Conceptual Structure of GCC). The code number of an insn is simply its position in the machine description. They are assigned sequentially to entries in the description, starting with code number 0.
gensupport.c
| Support routines for the various generation passes.
|
genconditions.c
| Calculate constant conditions.
|
genconstants.c
| Generate a series of #defines, one for each constant
named in a (define_constants ...) pattern.
|
genflags.c
| Generate flags HAVE_... saying which standard
instructions are available for this machine.
|
genconfig.c
| Generate some #define configuration flags.
|
gencodes.c
| Generate some macros CODE_FOR_... giving the
insn_code_number value for each of the defined standard
insn names.
|
genpreds.c
| Generate some macros CODE_FOR_... giving the
insn_code_number value for each of the defined standard insn names.
|
genattr.c
| Generate attribute information (insn-attr.h).
|
genattrtab.c
| Generate code to compute values of attributes.
|
genemit.c
| Generate code to emit insns as rtl.
|
genextract.c
| Generate code to extract operands from insn
|
genopinit.c
| Generate code to initialize optabs from
machine description.
|
genoutput.c
| Generate code to output assembler insns as
recognized from RTL.
|
genpeep.c
| Generate code to perform peephole optimizations.
|
genrecog.c
| Generate code to recognize rtl as insns.
|
gencheck.c
| Generate check macros for tree codes.
|
gengenrtl.c
| Generate code to allocate RTL structures.
|
genrtl.c
| Generated automatically by gengenrtl from
rtl.def.
|
gengtype.c
| Process source files and output type information.
|
genautomata.c
| Pipeline hazard description translator.
|
gengtype-lex.c
| A lexical scanner generated by flex
|
gengtype-yacc.c
| A Bison parser, made from gengtype-yacc.y.
|
gen-protos.c
| Massages a list of prototypes, for use by fixproto.
|
Table 4.1: A brief description of the various gen files. These
files are compiled to the programs that process the chosen machine
description to convert the information for internal use.
Synopsis: Support routines for the various generation passes.
This file has a number of functions that are useful at various points
of the target compiler generation. In particular,
init_md_reader and read_md_rtx are used to setup the
reading of a machine description file and reading a single rtx in it.
The function maybe_eval_c_test takes a string representing a C
test expression, looks it up in the condition table and reports
whether or not its value is known at compile time.
Synopsis: Calculate constant conditions.
Generates: insn-conditions.c
In a machine description, all of the insn patterns -
define_insn, define_expand, define_split,
define_peephole, define_peephole2 - contain an optional
C expression which makes the final decision about whether or not this
pattern is usable. That expression may turn out to be always false
when the compiler is built. If it is, most of the programs that
generate code from the machine description can simply ignore the
entire pattern.
Synopsis: Generate a series of #define statements, one for
each constant named in a (define_constants ...) pattern.
Generates: insn-constants.h
This program does not use gensupport.c because it does looks only at
the define_constants.
Synopsis: Generate flags HAVE_... saying which simple
standard instructions are available for this machine.
Generates: insn-flags.h
We scan the define_insn's and define_expand's in the
machine description and look at “instructions” with names that are
either not NULL or begin with any other character except a *. In
other words, the so-called “standard instructions” are accepted, the
rest are ignored. Thus we create a list of those “standard
instructions” that the given processor “knows”. An instruction in
the MD file could have an associated condition expressed in C. This
is the second “field” of the description of the instruction. The
genconditions program would have already looked at each of
these and memoized the compile time constants. The instruction
pattern is practically non existent if the condition is false. We
therefore, list out only those instruction patterns for which the
condition is known to be true or it's value is not known at compile
time. If the condition is known to be true, we define an
“existence” macro. If the condition is not known at compile time,
then we define the macro to be the condition itself. Note that the
genconditions program is concerned with the conditions in all
the RTL constructs, while we focus only on the “instructions”
constructs, i.e. define_insn and define_expand.
However, since the genconditions program has already looked at
all the condition expressions and memoized them, we directly use the
table that it constructs.
Synopsis: Generate some #define configuration flags.
Generates: insn-config.h
e.g. (am i sure that what follows is an example of the comment above ?) flags to determine output of machine description dependent #define's.
Synopsis: Generate some macros CODE_FOR_... giving the
insn_code_number value for each of the defined standard insn names.
Generates: insn-codes.h
Synopsis: Generate some macros CODE_FOR_... giving the
insn_code_number value for each of the defined standard insn names.
Synopsis: Generate attribute information (insn-attr.h).
Generates: insn-attr.h
Synopsis: Generate code to compute values of attributes.
Generates: insn-attrtab.c
Uses: genautomata.c (for pipeline hazard description
system in MD files)
This program handles insn attributes and the define_delay and
define_-function_unit definitions.
It produces a series of functions named `get_attr_...', one for each insn attribute. Each of these is given the rtx for an insn and returns a member of the enum for the attribute.
These subroutines have the form of a `switch' on the INSN_CODE (via `recog_-memoized'). Each case either returns a constant attribute value or a value that depends on tests on other attributes, the form of operands, or some random C expression (encoded with a SYMBOL_REF expression).
If the attribute `alternative', or a random C expression is present, `constrain_ope-rands' is called. If either of these cases of a reference to an operand is found, `extract_insn' is called.
The special attribute `length' is also recognized. For this operand, expressions involving the address of an operand or the current insn, (address (pc)), are valid. In this case, an initial pass is made to set all lengths that do not depend on address. Those that do are set to the maximum length. Then each insn that depends on an address is checked and possibly has its length changed. The process repeats until no further changed are made. The resulting lengths are saved for use by `get_attr_length'.
A special form of define_attr, where the expression for default
value is a CONST expression, indicates an attribute that is constant
for a given run of the compiler. The subroutine generated for these
attributes has no parameters as it does not depend on any particular
insn. Constant attributes are typically used to specify which variety
of processor is used.
Internal attributes are defined to handle define_delay and
define_function_unit. Special routines are output for these
cases.
This program works by keeping a list of possible values for each attribute. These include the basic attribute choices, default values for attribute, and all derived quantities.
As the description file is read, the definition for each insn is saved in a `struct insn_def'. When the file reading is complete, a `struct insn_ent' is created for each insn and chained to the corresponding attribute value, either that specified, or the default.
An optimization phase is then run. This simplifies expressions for each insn. EQ_ATTR tests are resolved, whenever possible, to a test that indicates when the attribute has the specified value for the insn. This avoids recursive calls during compilation.
The strategy used when processing define_delay and
define_function_unit definitions is to create arbitrarily
complex expressions and have the optimization simplify them.
Once optimization is complete, any required routines and definitions will be written.
An optimization that is not yet implemented is to hoist the constant expressions entirely out of the routines and definitions that are written. A way to do this is to iterate over all possible combinations of values for constant attributes and generate a set of functions for that given combination. An initialization function would be written that evaluates the attributes and installs the corresponding set of routines and definitions (each would be accessed through a pointer).
We use the flags in an RTX as follows:
`unchanging' (ATTR_IND_SIMPLIFIED_P): This rtx is fully simplified independent of the insn code.
`in_struct' (ATTR_CURR_SIMPLIFIED_P): This rtx is fully simplified for the insn code currently being processed (see optimize_attrs).
`integrated' (ATTR_PERMANENT_P): This rtx is permanent and unique (see attr_rtx).
`volatil' (ATTR_EQ_ATTR_P): During simplify_by_exploding the value of an EQ_ATTR rtx is true if !volatil and false if volatil.
Synopsis: Generate code to emit insns as rtl.
Synopsis: Generate code to extract operands from insn as rtl.
Synopsis: Generate code to initialize optabs from machine description.
Generates: insn-opinit.c
Many parts of GCC use arrays that are indexed by machine mode and contain the insn codes for pattern in the MD file that perform a given operation on operands of that mode.
These patterns are present in the MD file with names that contain the mode(s) used and the name of the operation. This program writes a function `init_all_op-tabs' that initializes the optabs with all the insn codes of the relevant patterns present in the MD file.
This array contains a list of optabs that need to be initialized. Within each string, the name of the pattern to be matched against is delimited with $( and $). In the string, $a and $b are used to match a short mode name (the part of the mode name not including `mode' and converted to lower-case). When writing out the initializer, the entire string is used. $A and $B are replaced with the full name of the mode; $a and $b are replaced with the short form of the name, as above.
If $N is present in the pattern, it means the two modes must be consecutive widths in the same mode class (e.g, QImode and HImode). $I means that only full integer modes should be considered for the next mode, and $F means that only float modes should be considered. $P means that both full and partial integer modes should be considered.
$V means to emit 'v' if the first mode is a MODE_FLOAT mode.
For some optabs, we store the operation by RTL codes. These are only used for comparisons. In that case, $c and $C are the lower-case and upper-case forms of the comparison, respectively.
Synopsis: Generate code to output assembler insns as recognized from rtl.
Generates: insn-output.c
This program reads the machine description for the compiler target machine and produces a file containing these things:
Since the code number of an insn is simply its position in the machine description, the following entry in the machine description
(define_insn "clrdf"
[(set (match_operand:DF 0 "general_operand" "")
(const_int 0))]
""
"clrd %0")
assuming it is the 25th entry present, would cause
insn_data[24].template to be "clrd %0", and
insn_data[24].n_operands to be 1.
Synopsis: Generate code to perform peephole optimizations.
Synopsis: Generate code to recognize rtl as insns.
Generates: insn-recog.c
This program is used to produce insn-recog.c, which contains a function called `recog' plus its subroutines. These functions contain a decision tree that recognizes whether an rtx, the argument given to recog, is a valid instruction.
recog returns -1 if the rtx is not valid. If the rtx is valid, recog returns a nonnegative number which is the insn code number for the pattern that matched. This is the same as the order in the machine description of the entry that matched. This number can be used as an index into various insn_* tables, such as insn_template, insn_outfun, and insn_n_operands (found in insn-output.c).
The third argument to recog is an optional pointer to an int. If present, recog will accept a pattern if it matches except for missing CLOBBER expressions at the end. In that case, the value pointed to by the optional pointer will be set to the number of CLOBBERs that need to be added (it should be initialized to zero by the caller). If it is set nonzero, the caller should allocate a PARALLEL of the appropriate size, copy the initial entries, and call add_clobbers (found in insn-emit.c) to fill in the CLOBBERs.
This program also generates the function `split_insns', which returns 0 if the rtl could not be split, or it returns the split rtl as an INSN list.
This program also generates the function `peephole2_insns', which returns 0 if the rtl could not be matched. If there was a match, the new rtl is returned in an INSN list, and LAST_INSN will point to the last recognized insn in the old sequence.
Synopsis: Generate check macros for tree codes.
Synopsis: Generate code to allocate RTL structures.
Synopsis: Generated automatically by gengenrtl from rtl.def.
Synopsis: Process source files and output type information.
Synopsis: Pipeline hazard description translator.
Synopsis: A lexical scanner generated by flex
Synopsis: A Bison parser, made from gengtype-yacc.y.
Synopsis: Massages a list of prototypes, for use by fixproto.
This is edition 1.0 of “The Phasewise File Groups of GCC”, last updated on January 7, 2008.
Copyright © 2004-2008 Abhijat Vichare , I.I.T. Bombay.
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, with the Front-Cover Texts being “The Phasewise File Groups of GCC,” and with the Back-Cover Texts as in (a) below. A copy of the license is included in the section entitled “GNU Free Documentation License.”(a) The FSF's Back-Cover Text is: “You have freedom to copy and modify this GNU Manual, like GNU software. Copies published by the Free Software Foundation raise funds for GNU development.”