Next: About this document
S. Sudarshan
Computer Science and Engineering Dept
I.I.T. Bombay
sudarsha@cse.iitb.ernet.in
http://www.cse.iitb.ernet.in/~sudarsha
Joint work with: Prasan Roy, S. Seshadri, Siddhesh Bhobhe
- Database Query Languages and Query Optimization
- Issues in common subexpressions
- DAG representation of alternative query evaluation plans
- Simple heuristics
- Greedy heuristic and optimizations
- Performance study
- Data represented in the form of tables
- Employee data: relation emp
1
|
emp-name | dept-name | age | sal |
| Sudarshan | CSE | 33 | 100,000 |
|
Phatak | SIT | 50 | 400,000 |
|
Prasan | CSE | 25 | 108,000 |
|
Arvind | SOM | 24 | 180,000 |
- Department data: relation dept
1
|
dept-name | dept-addr | head |
| CSE | CSE Bldg, IIT B | Dhamdhere |
|
SIT | Math Bldg, IIT B | Phatak |
|
SOM | SOM Bldg, IIT B | Korgaonkar |
- Database query languages are declarative
- Philosophy: say what you want, not how to get it
- Example: SQL
Q1: select emp.name, dept.addr
from emp, dept
where emp.dept-name = dept.dept-name
Q2: select dept-name, avg(salary)
from emp
where age < 35
group by dept-name
- Relational algebra: an algebra on relations
select: ()
join: ()
project: ()
aggregation: () - User level languages translated to relational algebra
- Multiple expressions for same result
(similar to (a+b)*c = a*b+a*c)
- E.g.
- Different expressions have different costs
- Query optimizer responsible for finding best expression
Why Multi-Query Optimization
- To tackle complex decision support queries
- Sequence (batch) of related queries
- Queries with common subexpressions
- Esp. with use of views and WITH clause
- Multi-output operators
E.g. Engage.Fusion
- Data warehouses, OLAP, ...
- Given: query, or a batch of queries
- Goal: exploit common subexpressions
- Problem: many alternative query plans with different costs
- E.g.:
- and -
no common subexpressions
- Rewrite : - now
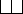 common
subexpression
common
subexpression - Can compute
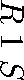 , store (materialize) and reuse
, store (materialize) and reuse
- Problem: expression form with CSE may or may not be cheaper!
- Problem: lots of alternative plans
 expensive
expensive
- Recognize possibilities of sharing
- Extend Volcano's Query-DAG generation algorithm
- Find best plan taking sharing into account
- Local best plans may not be globally optimal
- Exhaustive algorithms are doubly exponential
- Need good heuristics
- Plain Query Optimization
- System R: bottom-up
- Volcano: top-down, extensible
- Early MQO Papers
- Not integrated with basic optimizer tightly enough, inefficient
- Common Subexpression Elimination
- Invariants in Nested Queries
- Materialized View/Index Selection
- Needs to handle updates
- MQO is a subproblem
- Optimization in Presence of Materialized Views
AND-OR DAG Representation
-
 : equivalence nodes
: equivalence nodes -
 : operation nodes
: operation nodes
- Apply transformations
- E.g:
- Result of a transformation on E is equivalent to E.
Added under the same equivalence node - New equivalence nodes may be created
- Hashing based scheme for detecting duplicate derivations
used in Volcano (a.k.a hash consing)
- We use above for detecting common subexpressions
- Physical DAG models physical properties e.g. sort order
Detecting Repeated/Common Subexpressions
- Hashing scheme of Volcano
- gives ids to equiv. nodes
- hash function on (op, ids-of-inputs) help locate
duplicate operations
- detects identical expressions / (duplicate derivations)
- transformations create new equiv nodes iff expression
created is new
- Equiv. node parents of identical expressions different
common subexpression
- Additional unification step merges equivalence classes
- Given: and
- Given and
- Bottom-up traversal of the DAG adds new subsumption derivations
(and new equivalence nodes)
- Finds local best plan recursively, ignoring sharing possibilities
- Uses costlimit for a directed search (branch & bound)
- Cost of operation node = local cost + sum of input costs
- Cost of equivalence node = min cost of children
- Best plan of equivalence node:
lowest cost child, plus plans for its inputs
- Run plain Volcano on queries to find local best plans
- Find common subexpressions amongst local best plans
- Choose to materialize and share a common subexpression if:
- Note: recomp-cost changes depending on materialization
of descendants
- May choose to materialize and share only part of a common
subexpression
- Number of uses depends on which shared parents are materialized
- Given
- When optimizing
- Find best local plan, with special case for equivalence nodes
that are in best local plans for :
- set cost of node to min ( )
- Note: Once a node is chosen to be materialised, mat-cost is not
added for further sharing.
- After optimizing all s, run Volcano-SH to find and share
further common subexpressions (within queries)
- Compute DAG and best plans for each node using Volcano
- Find benefit of materializing each unmaterialized node
- mark a node n as materialized
- set cost of node n =
 of n
of n - recompute best plans for all nodes with above cost
- this step done incrementally
- of n +
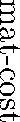 of n +
of n +
sum best costs for root of DAG - benefit of n = reduction in total cost due to materializing n
- unmark n, and unset cost of node n
- Choose node with max cost benefit,
mark it, materialize it and set its cost to - Repeat from Step 2, until no decrease in cost
Incremental Cost Update Propagation
- Recomputing best plans from scratch on each benefit computation
very expensive
- Observation:
Marking a node as materialized only affects its ancestors
- Incremental Propagation:
- Start from marked node, and propagate cost changes up the DAG
- If cost of a node does not change, no need to propagate
changes further up
- Use topological sort numbering to decide which node to
propagate changes to next (ensures no revisits)
Improvements to Greedy: Monotonicity Heuristic
- Monotonicity Assumption:
Benefit of materializing a node never increases as other nodes are
materialized.
- Monotonicity
old benefit estimates are overestimates on current benefit
- ``old''
 computed in an earlier iteration of greedy
computed in an earlier iteration of greedy - Key idea: Keep heap of nodes sorted on benefit overestimates
- Repeat forever
- Pop top node t
- If benefit t is , break
- if benefit of t is current, t is the node with
maximum benefit; delete from heap and materialize it
- else update its benefit, mark as current, reinsert in heap
- Monotonicity generally holds; reduces opt. run time by 90%
- Index Selection
- Nested Queries
- Parameterized Queries with common subparts
e.g. multiple calls on query/stored procedure with different
parameter values - Space Constraints
Greedy with benefit per unit space
- Implemented all algorithms (17K lines Volcano + 3K lines MQO)
- Benchmarks
- Stand-Alone TPCD
- Batched TPCD
- Scaleup
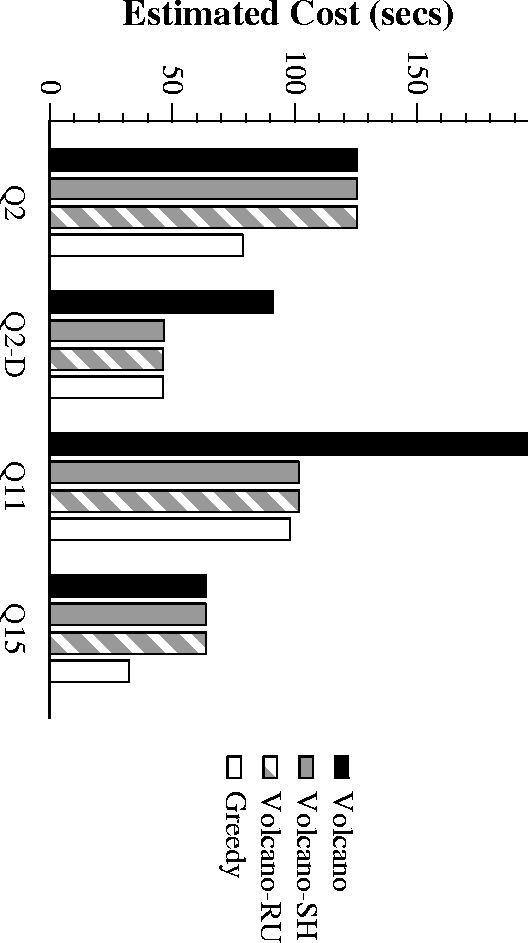
Performance of Stand-Alone TPCD
4.5in
4.5in
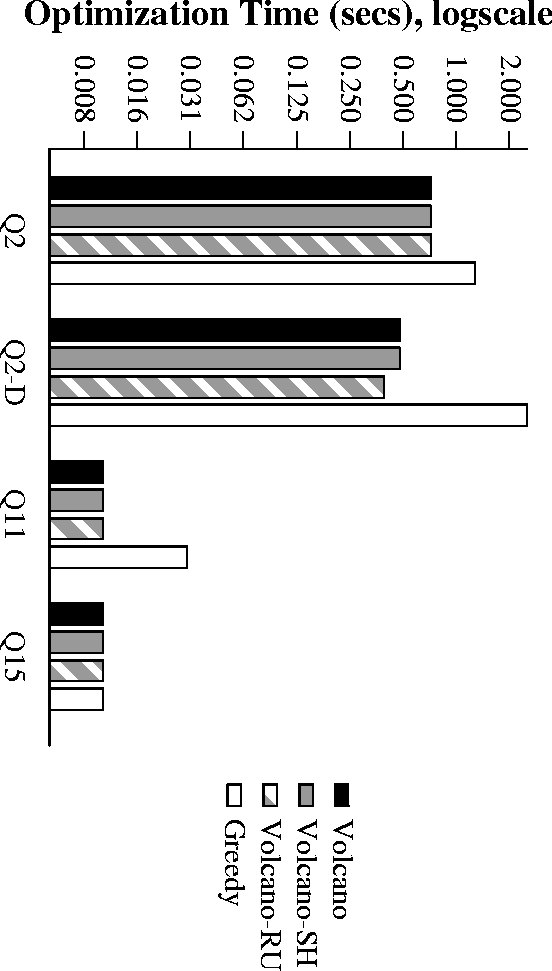
Performance on SQL-Server 6.5
3.0in
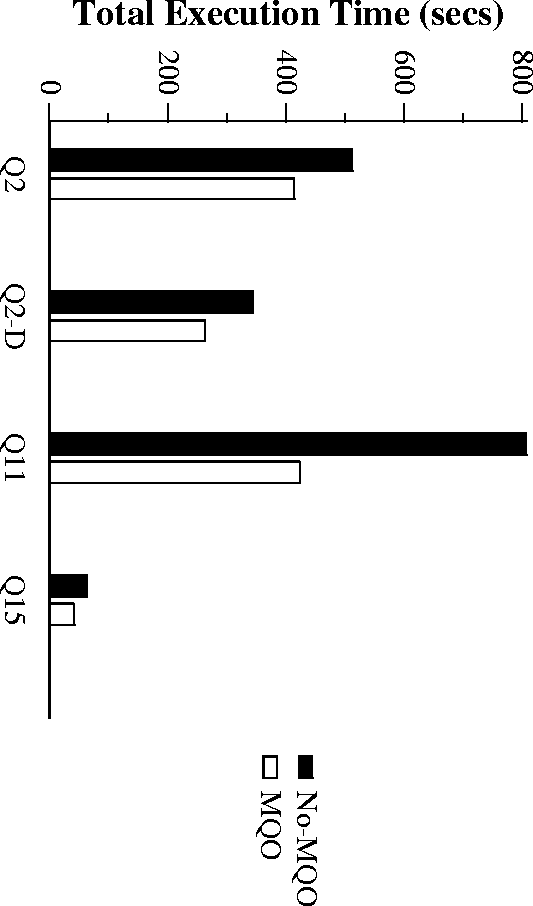
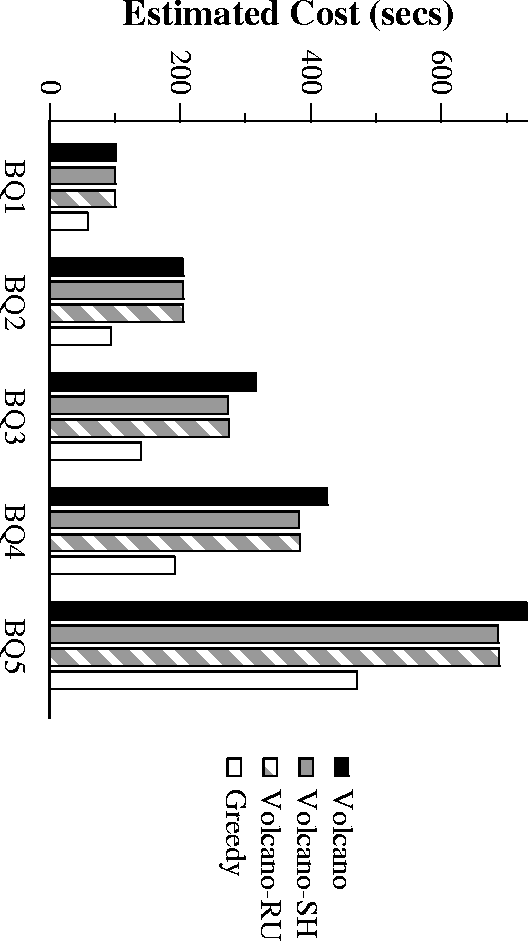
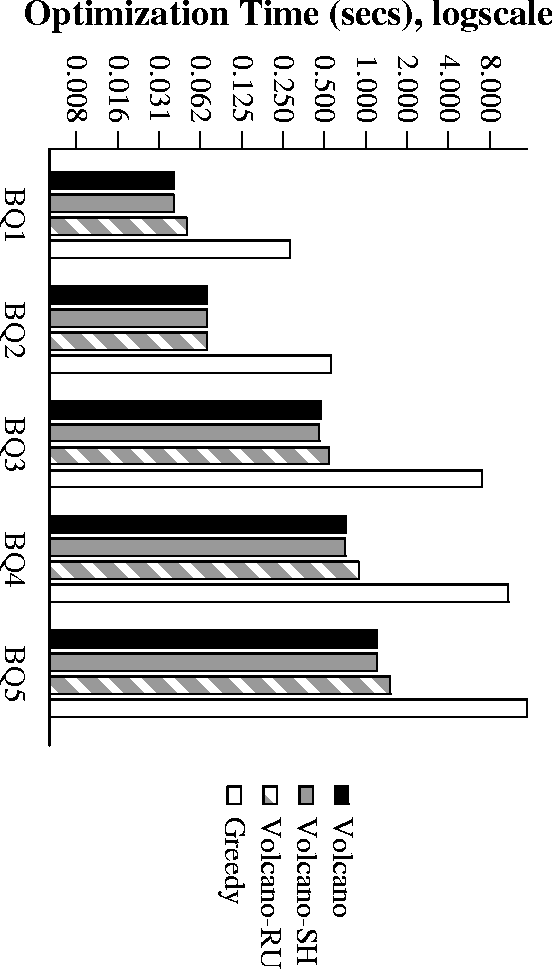
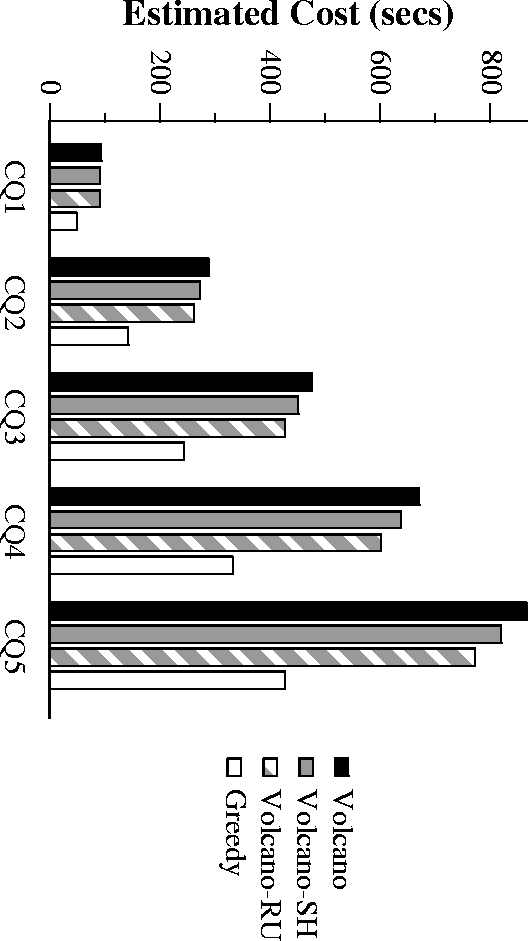
Performance of Batched TPCD
4.5in
4.5in
4.5in
4.5in
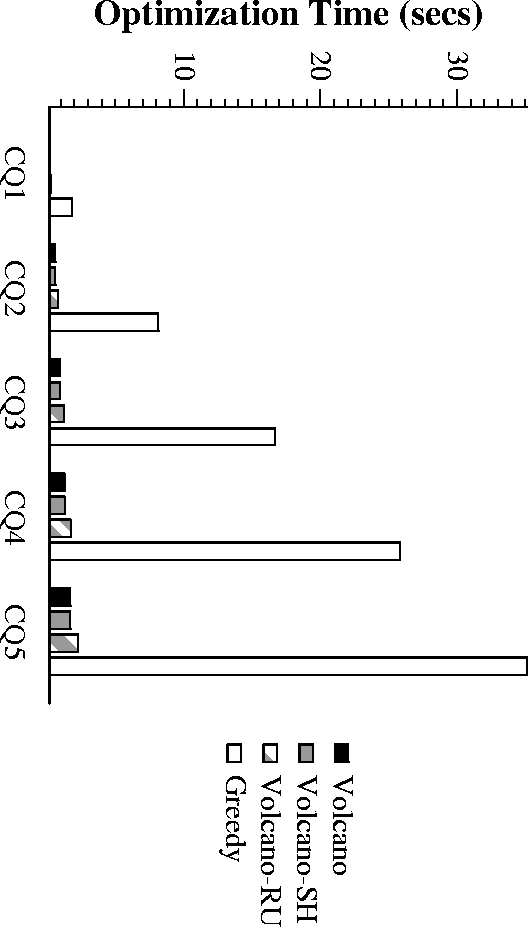
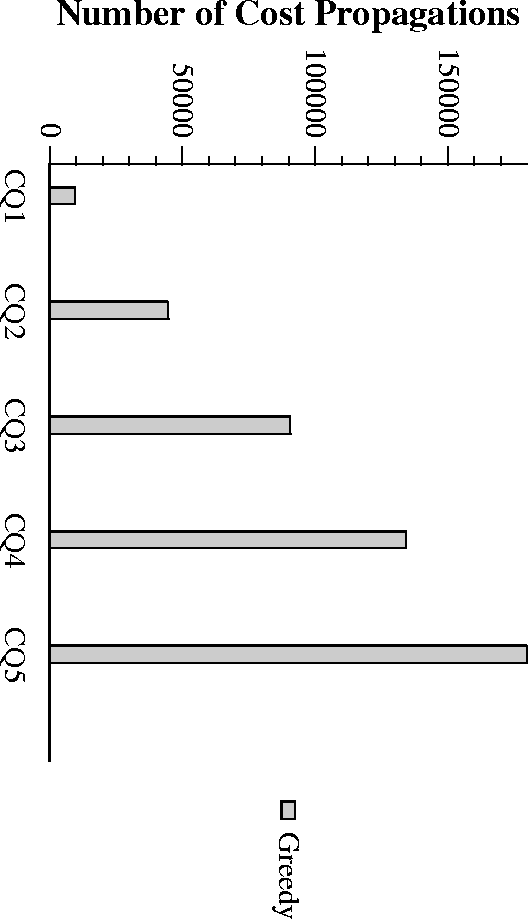
Empirical Complexity of Greedy
4.5in
4.5in
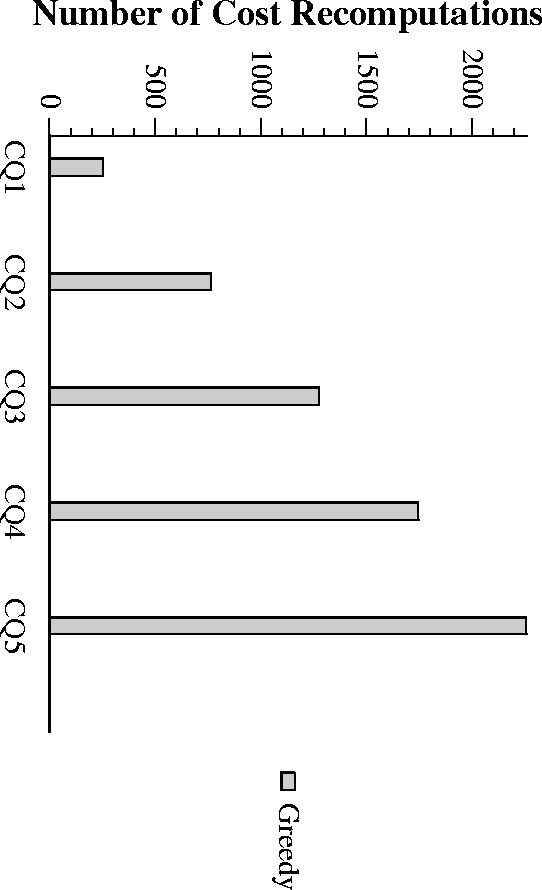
- Greedy is best overall, followed by Volcano-RU and Volcano-SH
- Volcano-SH, Volcano-RU have neglegible overheads.
Overhead for Greedy acceptable for complex expensive queries - Greedy shows linear scaleup with number of queries
- Benefits show up on TPCD benchmark running on Microsoft SQL-Server 6.5
- Advise:
Use Volcano-RU if query very cheap and syntactically complex.
Use Greedy for all other cases
- Space Constraints
- Query Caching
- Sequence of queries
- Need to predict future
- Decide what to maintain in the cache
- Large workloads: Query Abstraction
- Scheduling - try to avoid materialization
- View/Index Selection: Update Costs
Next: About this document
Ajay K Dhawale
Fri Apr 30 17:56:43 IST 1999