In this assignment, you will implement on-line TD algorithms with linear function approximation. Your testbed is an MDP that is popularly known as ``Baird's counterexample''. We stick with the version described by Sutton and Barto (1998, see Example 8.3), although the counterexample is originally from a paper by Baird (1995). You will have to experiment with two different updating schemes, and describe your results.
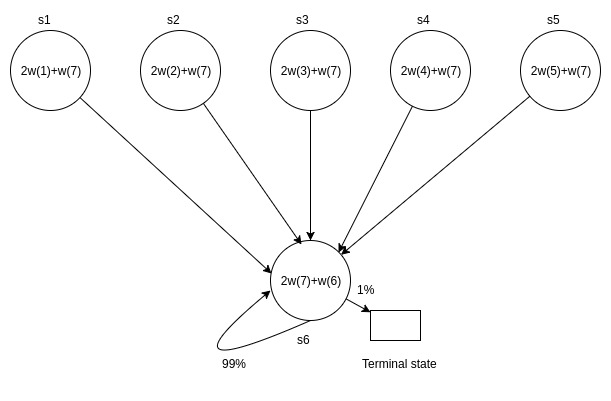
The MDP shown in the figure consists of 6 non-terminal states and 1 terminal state. It is an episodic MDP. Episodes start in one of the five upper states (picked uniformly at random), and proceed immediately to the lower state. When the agent takes (the only available) action in the lower state, it remains in the same state with probability 99%; with probability 1% it goes to the terminal state (and the episode ends). Take the discount factor γ to be 0.99. All rewards are zero rewards. By default the value of the terminal state is also taken to be zero.
Your aim is to perform policy evaluation: that is, to estimate the value function of the policy being followed. The value of each state is to be ``approximated'' as a linear combination of features. The parameters to be learned are coefficients w(1) through w(7). The actual approximations for each state are shown in the figure: for example, V(s2) ≈ 2 w2 + w7. It is easy to see that there exist several configurations of the weights that give the exact value function, which is uniformly zero. Your objective is to test two different TD variants for convergence to the zero value function, and so you will run the following two experiments. Assume that a total of N updates are performed.
You will submit two items: (1) working code which implements the two
experiments above, and (2) a report (as a single
file, report.pdf) containing graphs and answers to the
questions given below.
Create a directory titled [rollnumber]. Place all your source and
executable files, along with the report.pdf file in this
directory. The directory must contain a shell script
named startmdp.sh. You are free to implement your
algorithm in a programming language of your
choice. startmdp.sh should take command-line arguments in
the following sequence.
Here are a couple of examples of usage.
./startmdp.sh 1 10000 0 1 1 1 1 1 10 1./startmdp.sh 2 5000 0.2 -1.2 1 14 1 1 10 1The output of the script must be the estimated value function after each TD update. Each line must have 6 values (in sequence for states s1 through s6) separated by spaces. There must be a total of N lines. Make sure that your script does not output anything other than these 6N numbers.
Your code will be tested by running an experiment that calls
startmdp.sh in your directory with a valid set of
parameters. Before you submit, make sure you can successfully
run startmdp.sh on the sl2 machines
(sl2-*.cse.iitb.ac.in).
Along with these answers, the report should also include any relevant details about your implementation of the algorithms.
Place all the data generated from your experiments, as well
as report.pdf, within a directory
called report, and place this directory inside your
submission folder ([rollnumber]).
In summary: you must submit your [rollnumber]
directory (compressed as
submission.tar.gz) through Moodle. The directory must contain
startmdp.sh, along with all the sources and
executables. The report directory must contain all the
data generated by your experiments, and a file
called report.pdf
Your code will be tested for correctness on each experiment (2 + 2 marks); your answers in the report carry 3 marks, 2 marks, and 1 mark, in sequence.
The TAs and instructor may look at your source code and notes to corroborate the results presented in your experiments, and may also call you to a face-to-face session to explain your code.
Your submission is due by 11.55 p.m., Friday, November 10. You are
advised to finish working on your submission well in advance, keeping
enough time to test it on the sl2 machines and upload to
Moodle. Your submission will not be evaluated (and will be given a
score of zero) if it is not received by the deadline.
You must work alone on this assignment. Do not share any code (whether yours or code you have found on the Internet) with your classmates. Do not discuss the design of your agent with anybody else.
You will not be allowed to alter your code in any way after the
submission deadline. Before submission, make sure that it runs for a
variety of experimental conditions on the sl2
machines. If your code requires any special libraries to run, it
is your responsibility to get those libraries working on
the sl2 machines (go through
the CSE bug tracking
system to make a request to the system administrators.)