 TWO
FORCES are shaping the future of the web away from generic portals to specific
portholes --- search and directory sites that are targeted to web-mature
audiences interested in deep, high-quality information on specific subjects,
sites that trawl for the needles and leave the haystacks alone. TWO
FORCES are shaping the future of the web away from generic portals to specific
portholes --- search and directory sites that are targeted to web-mature
audiences interested in deep, high-quality information on specific subjects,
sites that trawl for the needles and leave the haystacks alone.
One force is the exploding volume of web publication. The major web crawlers harness dozens of powerful processors and hundreds of gigabytes of storage using superbly crafted software, and yet cover 30-40% of the web. Scaling up the operation may be feasible, but useless. Already, the sheer diversity of content at a generic search site snares all but the most crafty queries in irrelevant results. The second force is the growing mass of savvy users who use the web for serious research. Although keyword search and directory browsing are still essential services, these are no longer sufficient for their needs. They need tools for ad-hoc search, profile-based background search, find-similar search, classification, and clustering of dynamic views of a narrow section of the web. There is growing consensus that small is beautiful: as the web grows, a large number of portals, each of which specializes deeply in a topical area, will be preferable to universal, one-size-fits-all search portals. The following recent articles bear testimony to this imminent trend.
|
Can focused portals be constructed automatically?In this project I am investigating how to build a focused portal automatically, starting from a handful of examples on a specific topic, while minimizing crawling time and space in irrelevant and/or low-quality regions of the web. I envisage that crawling will become a lightweight activity at the level of individuals and interest groups. There will be hundreds of thousands of focused crawlers covering diverse areas of web information, tailored to the needs of specific communities. |
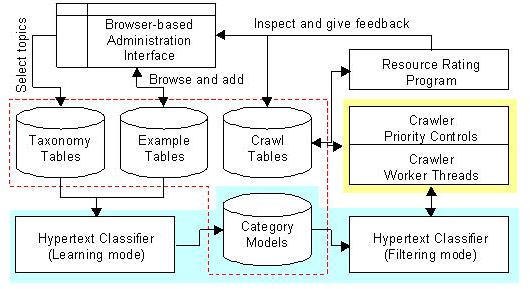 The prototype
focused crawler that I have built consists of two text mining systems that
guide the crawler. One is an automatic hypertext topic classifier
that stamps each document with a score of relevance. The relevance
score reflects how interesting the page is, given the topic of the crawl.
The other continually updates a resource rating. This rating
is an estimated benefit of crawling out from the page's out-links. The prototype
focused crawler that I have built consists of two text mining systems that
guide the crawler. One is an automatic hypertext topic classifier
that stamps each document with a score of relevance. The relevance
score reflects how interesting the page is, given the topic of the crawl.
The other continually updates a resource rating. This rating
is an estimated benefit of crawling out from the page's out-links. |
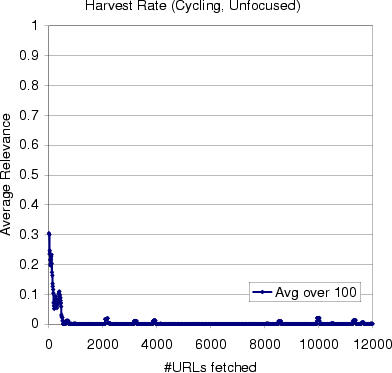 The main
challenge is to ensure a high harvest rate: the fraction of page
fetches which are relevant to the user's interest. Without the
hypertext
classifier, an ordinary crawler has no hope of keeping on track.
We started an ordinary crawler from a set of 50 bicycling pages, and within
the first few hundred page fetches, it was completely lost in web terrain
having nothing to do with bicycling. The quickly decaying plot of
relevance against time shows that on the web, harvesting relevant content
is non-trivial. The main
challenge is to ensure a high harvest rate: the fraction of page
fetches which are relevant to the user's interest. Without the
hypertext
classifier, an ordinary crawler has no hope of keeping on track.
We started an ordinary crawler from a set of 50 bicycling pages, and within
the first few hundred page fetches, it was completely lost in web terrain
having nothing to do with bicycling. The quickly decaying plot of
relevance against time shows that on the web, harvesting relevant content
is non-trivial. |
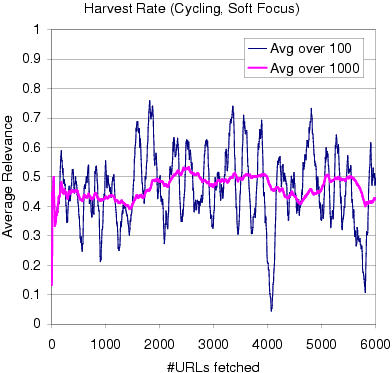 It is
crucial that the harvest rate of the focused crawler be high, otherwise
it would be easier to crawl the whole web and bucket the results into topics
as a post-processing step. To our delight, our prototype, starting
from the same 50 URLs, kept up a healthy harvest rate, collecting relevant
pages almost half the time. Within one hour on a small desktop PC,
we trawled over 3000 pages relevant to bicycling. We did not need
any dependence on a general crawl and index of the web, or an existing
search service. It is
crucial that the harvest rate of the focused crawler be high, otherwise
it would be easier to crawl the whole web and bucket the results into topics
as a post-processing step. To our delight, our prototype, starting
from the same 50 URLs, kept up a healthy harvest rate, collecting relevant
pages almost half the time. Within one hour on a small desktop PC,
we trawled over 3000 pages relevant to bicycling. We did not need
any dependence on a general crawl and index of the web, or an existing
search service. |
The resource rating system runs concurrently with the crawler to identify
a few strategic nodes in the web graph from which a large number of relevant
sites can be reached within a few links. The reader is encouraged
to check out the top choices for bicycling:
http://www.truesport.com/Bike/links.htm |
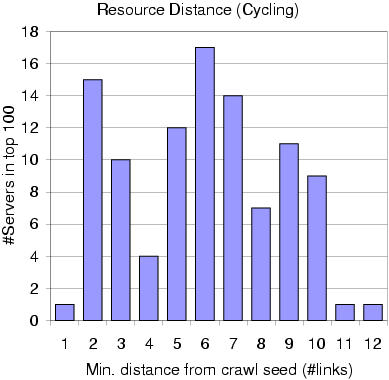 Keyword
searches could very easily miss these great pages. The starting set
of URLs were those that Alta Vista returned in response to the query "bicycling"
and all pages that were one link from the query responses. In spite
of this distance-one expansion, it was found that most of the top 100 strategic
nodes were quite far from the starting set, up to 12 links away.
An ordinary crawler would encounter millions of pages within this radius,
most of them not about bicycling! The graph also proves that the
start set was not very favorable, and the focused crawler had to do non-trivial
work to distill the above sites. Keyword
searches could very easily miss these great pages. The starting set
of URLs were those that Alta Vista returned in response to the query "bicycling"
and all pages that were one link from the query responses. In spite
of this distance-one expansion, it was found that most of the top 100 strategic
nodes were quite far from the starting set, up to 12 links away.
An ordinary crawler would encounter millions of pages within this radius,
most of them not about bicycling! The graph also proves that the
start set was not very favorable, and the focused crawler had to do non-trivial
work to distill the above sites. |
Similar results were obtained across diverse topics such as AIDS/HIV,
mutual funds, gardening, and pharmaceuticals, to name a few.
Papers and sites related to the Focus project
|