Language supported by
Sclp
|
The language supported by sclp is based on
C with several simplifications and some enrichments. We describe
it in terms of data types, values, operations on them, and data
and control constructs. This description is based on the current
design. The language and sclp is a work in progress and will be
updated later.
Data type, values, and
operations on values
sclp supports integers, floating point numbers, booleans values,
and strings:
- Integer (
int)
and floating point (float)
numbers have the usual semantics in C (4 byte values for
integers and 8 byte values for floating point numbers). They
appear as constants in programs and new values can be
computed using the following arithmetic operators: ternary
operator ?:
(conditional expression); binary operators +,
-, *, /;
and unary operator -.
They can be compared using the comparison operators <, <=,
>,
>=,
!=, and ==. These
values can be read from standard input and can be
printed on standard output. The floating point
numbers appearing in the program are accepted only
in decimal point format. However, the spim
input-output support accepts without a decimal
point as input value for a floating point
variable.
- Unlike C, integers are not
interpreted as boolean values. Instead there is a type
called
bool and
boolean values are computed using the comparison operators.
They
can be assigned to variables and can be operated by the
boolean operators &&,
||, and !. Note
that boolean values do not have a concrete syntax to appear
in the programs and thus we cannot use true or false as
constants in a program. (This design choice has been made to
keep the number of classes in sclp implementation small,
primarily for rolling out a reference implementation on
time; it may change later.) If true and false values
are required, they can be computed by assigning comparison
expressions such as 3>5 (for
false value) and 3<5
(for true value) to variables declared as bool.
These values cannot be read from standard input or printed
on standard output.
- The strings (
string)
supported by sclp appear as sequences of characters in a
pair of double quotes (").
There are no operators on strings (nor any library
functions) to compute strings or compare them. They can be
assigned to variables and can be passed around from a
variable (declared as string) to another through
assignments. They cannot be read from standard input but can
be printed on standard output. Since there are no
operations on strings, they are not null terminated.
Besides, there is no escape character and hence a double
quote cannot appear within a string.
Language Constructs
At the moment, the language supports
scalar values (int,
float, bool, string), pointers and
multi-dimensional arrays. Pointers can point only to scalars
and arrays can contain only scalars. There are no user defined
types. Pointers and arrays are written in the usual C syntax.
The computations in a program are
organized using the following constructs:
- A program is contained in a
single file (i.e. separate compilation is not
supported).
- Comments can be
introduced in C++ style. They
ignore everything appearing after
//
until the end of the line
containing it.
- There are three kinds of expression:
arithmetic, comparison (or relational), and boolean.
- The arithmetic operators have
higher precedence than the relational operators which in
turn have a higher precedence than the boolean operators.
Within a group of operators (arithmetic, relational, and
boolean), the operators have the usual precedences. The
relational operators are non-associative; other operators
have the usual associativity as in C.
- The arithmetic expressions can be
used in comparison expressions (but not the other way
round), which in turn, can be used in logical expressions
(but not the other way round). Also, no operator accepts
values of different types. All expressions are free of
side effects, i.e. pre- or post- increment or
decrement operators (
++
or --) are
not supported. Note that as a consequence of this
decision, --x
is -(-x) in
our language and so is --5
(whose value is 5) which is an error in C (side-effect
operators can work only on variables).
- An arithmetic expression (or a
comparison expression) takes the arguments of either
int type or float
type but they are not allowed to be mixed. For example
the expression a+b<c+d
is a valid relational expression with the implied
(syntactic) grouping (a+b)<(c+d);
the compiler does not treat the grouping as a+(b<c)+d
because it is invalid as an arithmetic expression. As
a consequence, the expressiona<b+c<d
is invalid under sclp semantics with any grouping.
Similarly, the expression a<b&&c<d
is a valid logical expression with the implied
grouping (a<b)&&(c<d)
but a possible grouping a<(b&&c)<d
is invalid as a relational expression. Note that some
of these distinctions cannot be made purely
syntactically and semantic actions are used for
prohibiting these errors. Hence some of these errors
are not detected when the -sa-parse
switch which disables the semantic actions, is used.
In summary, relational operators do not take boolean
or string operands. Bolean operators take only boolean
values as operators.
- The result of ternary expression can
be a boolean or a string value too.
-
Expression (a<b)&&(c<d)
can also be written as a sequence of
statements x =
a<b; y = c<d; z = x&&y;
where x,
y,
and z,
have been declared as bool
variables.
- Note
that an assignment is not an expression. Hence
unlike C, the assignment operator
= cannot appear
within an expression and a=b=c
is disallowed.
Operators have the following
precedences and associativities. The higher numbers
indicate higher precedence. In the type signature below
represents the bool
type,
can be either int
or float type,
and
can be one of the int,float, bool,
or string
type.
Precedence Level
|
Operator Group
|
Operators
|
Type Signature
|
Associativity
|
1 (lowest)
|
Ternary Expression
|
?, :
|
|
Right
|
2
|
Boolean
|
||
|
|
Left
|
3
|
&&
|
|
Left
|
4
|
!
|
|
Right
|
5
|
Relational
|
!=,
==, <, <=, >, >= |
|
Non-associative
|
6
|
Arithmetic
|
+, -
|
|
Left
|
7
|
*, /
|
|
Left
|
8 (highest)
|
- (unary)
|
|
Right
|
- Statements
represent the executable instructions and include the
following.
- Assignment
statements are
terminated by a semicolon. A variable of a given type can only
be assigned the values of the same type.
- Selection statements type
if
and if-else
- Iteration statements
while
and do-while
in the usual C syntax. Other statements
such as for,
switch,
and
goto
are
not supported as of now.
- Compound statement contain a
sequence of statements in a pair of braces (
{ and }).
Unlike C, compound statements cannot include
declarations. Compound statements can be empty
(i.e., { }
is a valid compound statement).
- Unlike C, expressions
terminated by a semicolon do not become
statements.
Function calls are in C
syntax. Unlike C, function
calls do not appear as operands of
expressions. A function call may appear in the
right hand side of an assignment or may be
terminated by a semicolon to become an
independent statement. If the result of a
function is required in an expression, it must
be assigned to a variable and the variable
used in the expression. A function may be
defined anywhere but its prototype declaration
must appear as a global declaration.
- Print statement prints the
value of a variable of the typles
int, float,
or a string
(but not bool),
and constants of type int,
float,
or a string.
A bool
value has no concrete syntax hence there is no
question of printing it. Unlike C, there is no
format string for printing.
- Read statement reads the
value of an
int
or a float
variable. Strings cannot be read from the
input. They can only appear as constants in
the program. Unlike C, there is no format
string for reading.
- Return statement that
returns a value for a value-returning
function.
- All statements can appear
only within a function body. Thus there are no
static initializations, unlike C.
- Functions have optional
parameters and optional return value. Function
headers are specified in C syntax and are
followed by a compound statement. A void
function does not return a value and hence does
not contain a return statement. Besides, a
function may not have parameters. Similar to C,
functions are not nested. They may have local
variables and may also access global variables.
Function prototypes must precede function
definitions. Function names cannot be used as
variables.
- Declarations are in C syntax
(type specifier followed by a comma separated
list of variables terminated by a semicolon).
All local declarations must appear in the
beginning before any executable statement (and
hence declarations may not contain
initializers). Global declarations of variables
and functions may be interleaved but every
function call or occurrence of a variable must
be preceded by its declaration. As usual, local
declarations shadow the global declarations in
that it is okay for both of them to have a
variable with the same name but the global
declaration of variable becomes invisible, i.e.
a use of the variable correspond to its local
declaration.
- As
usual, a variable name (or a function
name) is a sequence of letters (underscore
"_" inclusive) or digits but must begin
with a letter. All
keywords (for introducing types and statements)
are reserved and cannot be used as names.
Several example of valid programs have
been provided below. The finer details of the language can be
discovered by creating examples and running them through the
reference implementation.
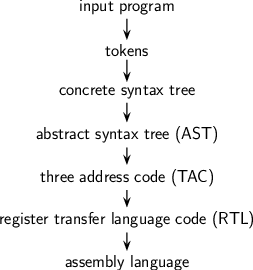
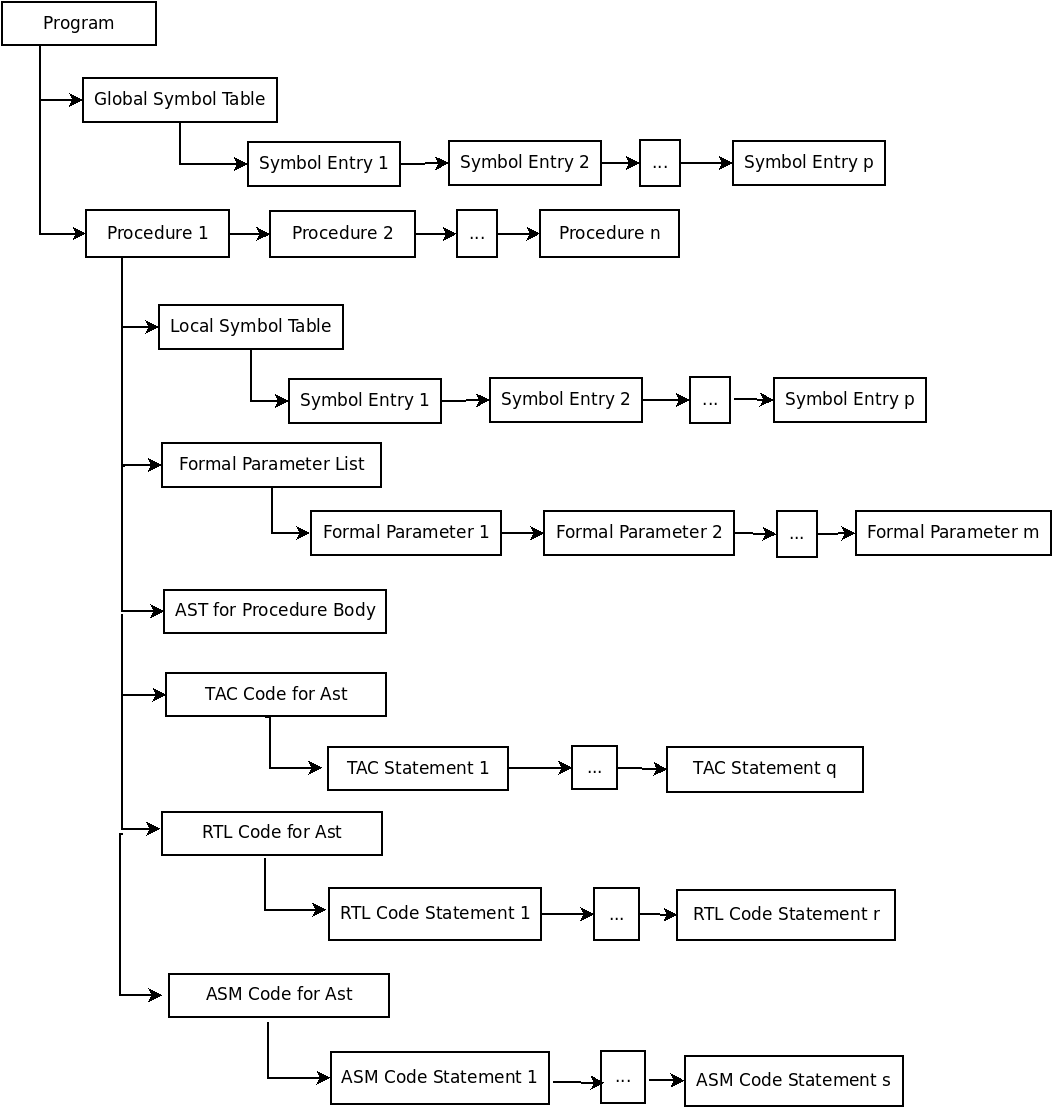
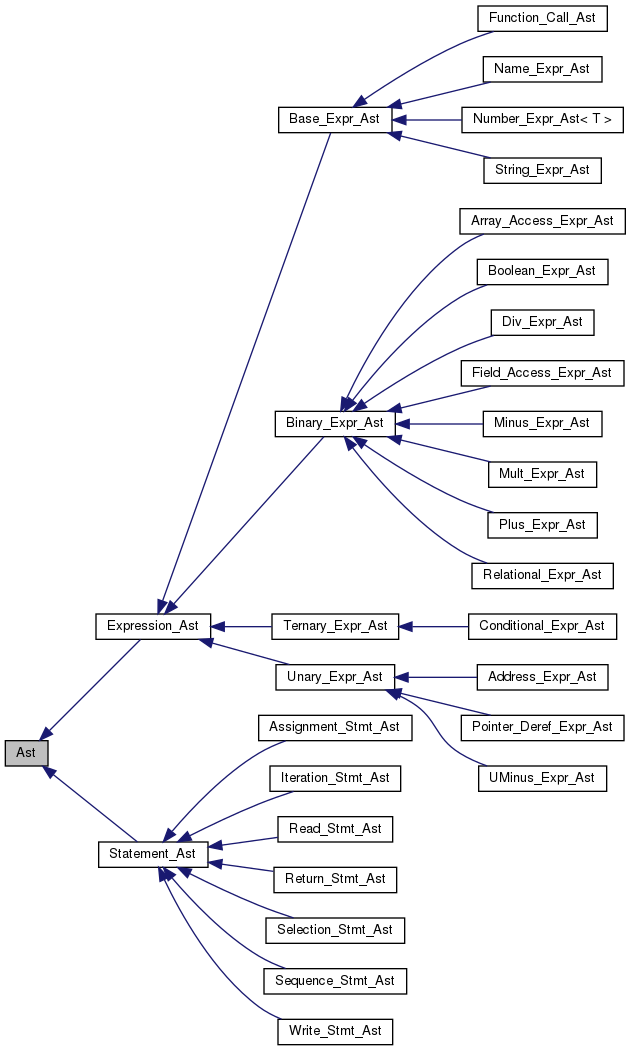
Sclp compiles a program by constructing a series of intermediate representations
(IRs) such that each IR is computed from the earlier IR.
Sclp embodies object oriented design and
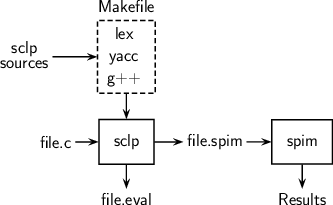
implementation. The implementation language is C++. Parser and scanner are
implemented using lex and yacc (lex/flex
manual, yacc/bison
manual, lex &
yacc book). The overall compilation flow is the
classical sequence of various phases as illustrated below.