Data
Understanding videos via captioning has gained a lot of traction recently. While captions are provided alongside videos, the information about where a caption aligns within a video is missing, which could be particularly useful for indexing and retrieval..

Characteristics
CLARIFICATION
For localizing sentences/captions in videos that leverages both audio and video modalities and that can generalize to new and possibly low-resource language settings.Moreover, it is a rich new dataset, whose annotation is driven by both audio and visual modalities and which is richer in the audio modality than previous datasets. Further, MALTA has sentences in two languages (including the language of the speech in the audio modality).
Till time existing datasets have data of videos and their relevant sentences/captions in english but MALTA has data of videos, sentences/captions and audio too ! These audios are in rich Marathi language, while the sentences/captions are in marathi as well as in english language.
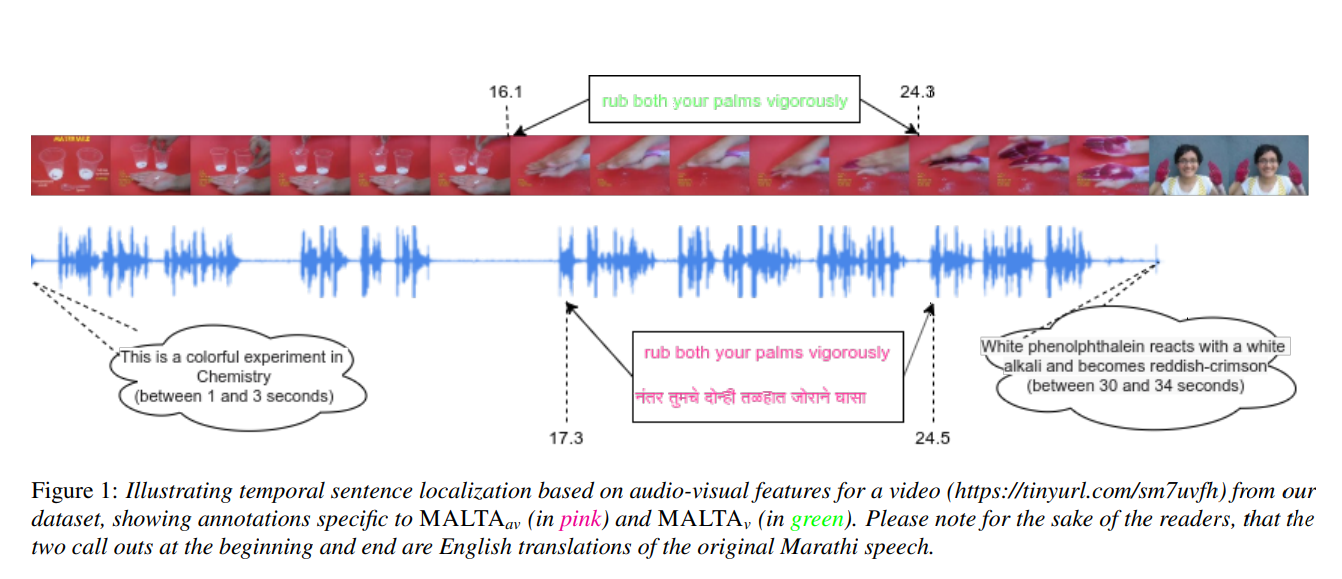
In MALTA_V, english transcripts are aligned by attending to video alone. While in MALTA_AV, marathi transcripts are aligned by attending to video and audio also.
We empirically demonstrate on MALTA, it is effective even when the language of the speech in the videos (Marathi) is different from the language in which the sentences are expressed (English). Even with the mismatch in language, we see a significant improvement in using the audio modality with CONC-AV compared to using only the video modality.