We propose a novel Hierarchical Model for learning semantics from video in an unsupervised way. Our method learns semantic dictionaries in all the semantic levels of video hierarchy. These semantic dictionaries are then used to annotate the video in terms of dictionary units. The information is learned from pixel level and passed to the higher levels till shot. The annotated tags represents learned semantics and reveals structural information as well.
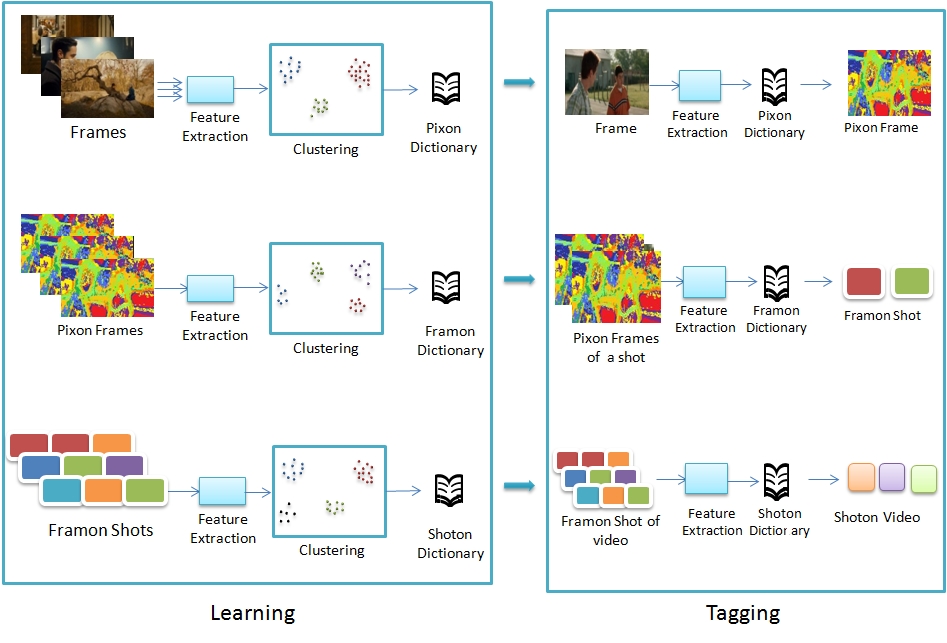
Our model provides video semantic information as annotations which helps in building video retrieval applications. In this section, we first introduce our algorithm for building Videon model and present various comparison schemes which can be used by retrieval applications. Our model first extracts Pixon from the pixels, the basic dictionary units. This results in pixon frames, shots and video. In the next level, the pixon frames are examined for their distribution and structure to form Framon. Representing each frame as a framon results in one dimensional framon shots and video. These framon shots are further analyzed to extract Shotons. This results in shoton video, which is a one dimensional array of shotons, where each shot corresponds to one element in the array. This is illustrated in the above Figure.
Pixons
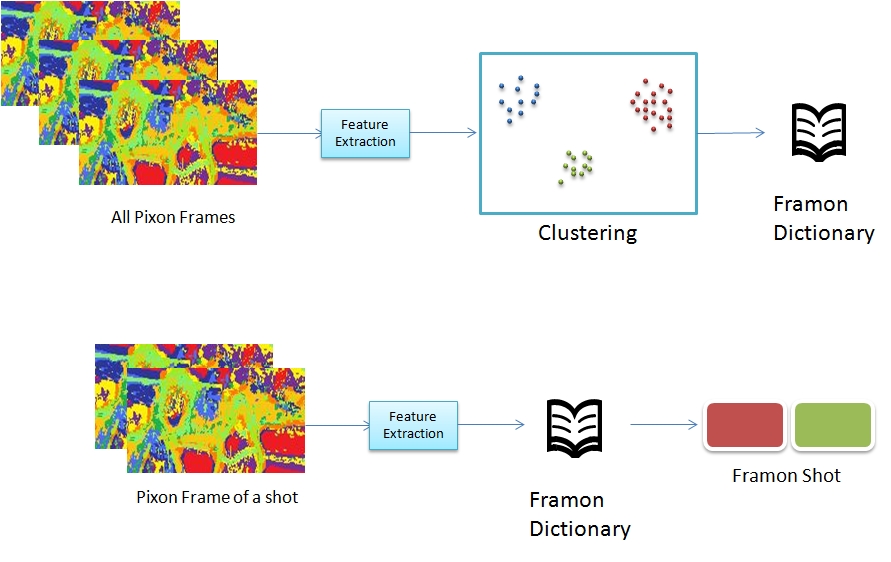
Pixon, the basic dictionary unit, captures property of pixels in a given window. This is derived from the image and motion features. From each window of pixels, we extract features using pyramidal Gaussian, neighborhood layout and edge filters.

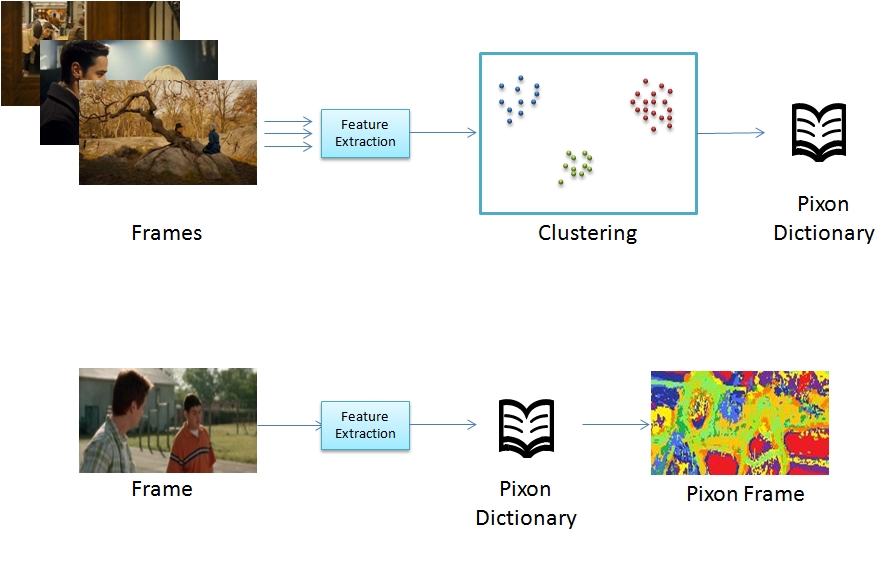
These features extracted from the complete video, are clustered. These cluster centers form pixons.
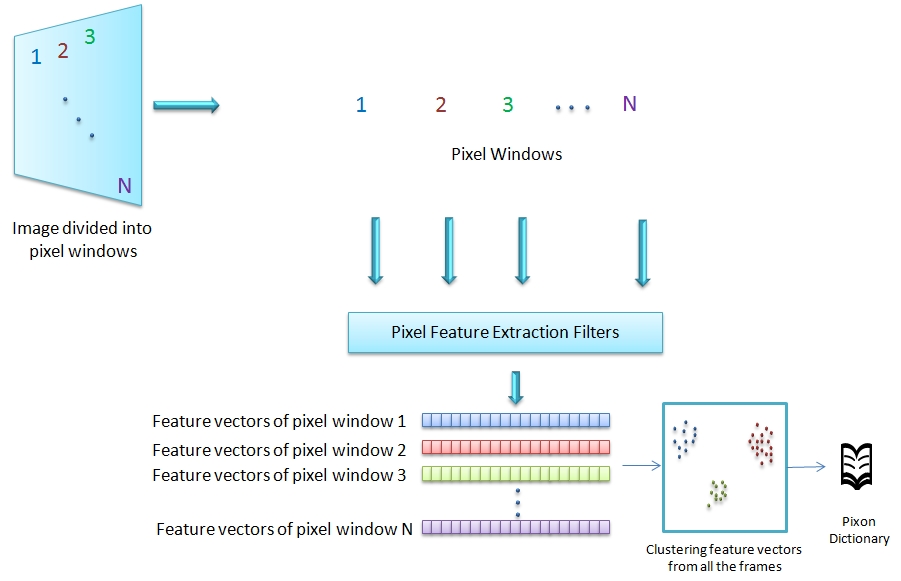
Using this pixons, each window of pixels are represented by a single pixon. Thereby, we represent each frame as pixon frame and the video as 3D array of pixons. This pixons capture the distinctions in terms of image colour and motions.
Clustering feature vectors extracted from the entire video consumes lot of memory and computation power. We optimize the clustering part, by extracting pixon at each hierarchy level using the feature vectors of lowerlevel pixon. We start by extracting pixon for each frame. For each shot, feature vectors corresponding to pixon of the frames are used rather than the feature vector of the entire pixel groups. We then use pixon from shots to extract pixon of video. This saves lot of time and lets our model handle video of any length efficiently without compromising accuracy. This optimization is used while forming the dictionary units at higher levels of hierarchy.
Framons
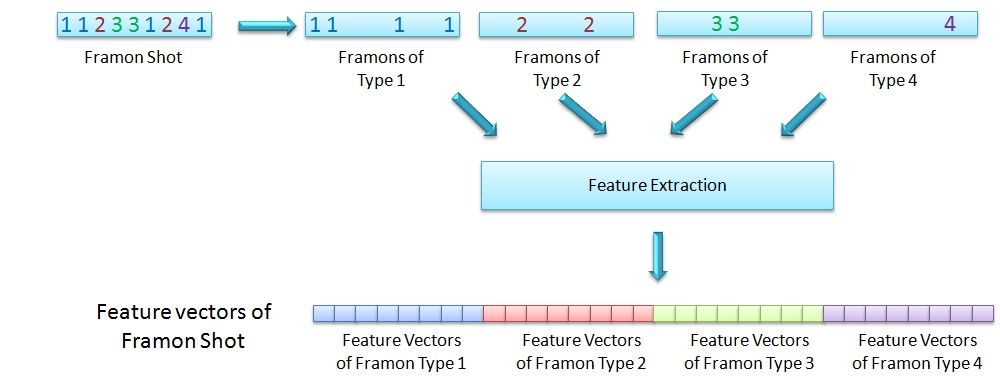
Framon, a unit which represent frame, is extracted by capturing the distribution of pixon in the pixon frame. From each pixon frame, histogram and geometric features are extracted, as show in the Figure below.

The pixon frames are splitted into frames containing unique pixon. These features are applied on each such frame corresponding to pixons in the dictionary. This is illustrated in the Figure below.
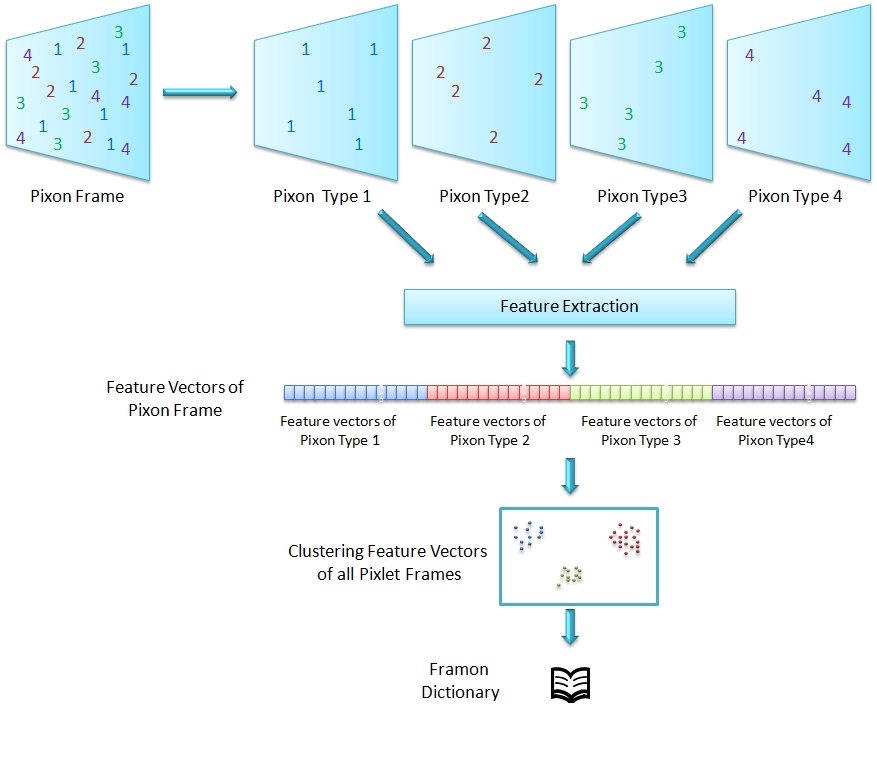
The histogram features include the normalized histogram of pixon. The geometry features and extracts number of independent regions, areas of the regions, minimum, maximum & average distance between these regions. framons are formed by clustering these features and selecting cluster centers. Every frame is mapped to a Framon and hence we represent every shot as a one dimensional framon sequence to get a framon shot and similarly the video is also represented as one dimensional array of framon sequence giving us a framon video. This is demonstrated in the Figure below.
Representing video as a one dimensional array of semantic units plays a great role in designing video retrieval applications. First, the video is presented in a simple format of semantic units making it easy for developers. Second, the computation time of the new applications built using framons are reduced enormously, as they now can operate on one dimensional array instead of three dimensional video data. Third, the one dimensional representation of semantic units is applicable to all semantic level higher than frame, making the video as compact as possible.
Shotons
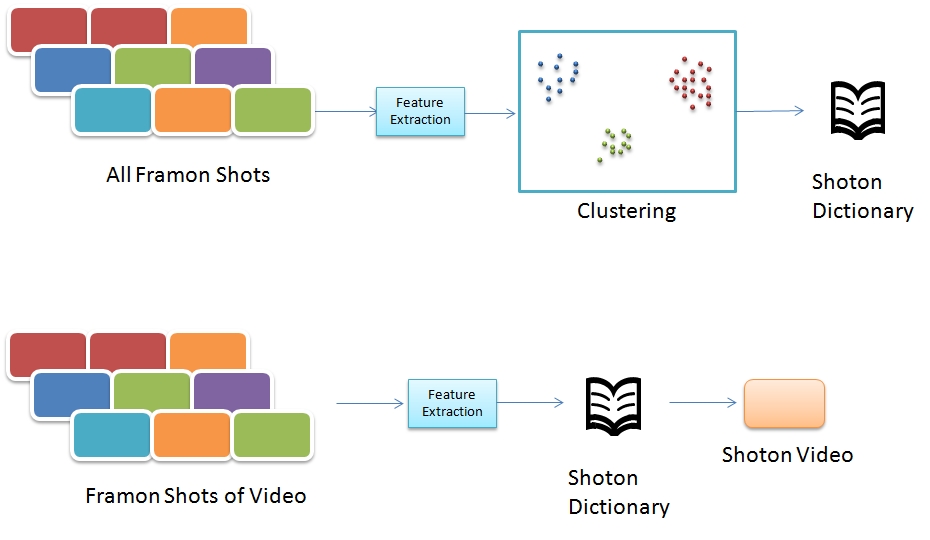
In the next level of hierarchy, the content of the shot is represented by shoton, which is extracted by capturing the distribution of framons in the framon shot. Similar to features extracted from pixion frame to get framons, we extract histogram and geometry features from framon shots. The histogram features include the normalized histogram of framons. The geometry feature captures connectivity of each framon through the following features: number of independent blocks, length of each blocks, minimum, maximum & average distance between these blocks.

We then represent cluster the extracted features to form shoton dictionary.
Using this dictionary, video is represented as a one dimensional shoton sequence, which we call as shoton video, where the length of the sequence is equal to the number of shots in the video.
Shoton is a more powerful visualization of video, as it lets us compare shots easily. Shot, being a higher-level semantic unit, is used to build next hierarchical units like scene & story. Readily providing abstractions of shots makes the task easier. Moreover, providing shot semantics has huge impact on many similarity and classification applications, where the sequence of type of shots, is important. Example applications include sports score detection; news story detection; separating professor, students and board from lecture video, classifying video based on the common shot type in the video.
Comparison Scheme
Video similarity is computed by comparing dictionary units of the video. However, the dictionaries across video are not same, hence we have to establish similarity between the dictionaries to compare them. As we have features associated with every dictionaries, the task is simplified to establishing similarity between the corresponding feature vectors. There are many ways in which the similarity can be established between these feature vectors. The simplest way is to map the dictionary units of one video to the other video using Euclidean distance. This is a good similarity measure which works in many cases, and enables us to compare videos quickly. However, as the number of dictionary units in one video is reduced or increased to match other video, there is an approximation, which could be a problem in some cases.