Prof. Ganesh Ramakrishnan
Impactful Research Award
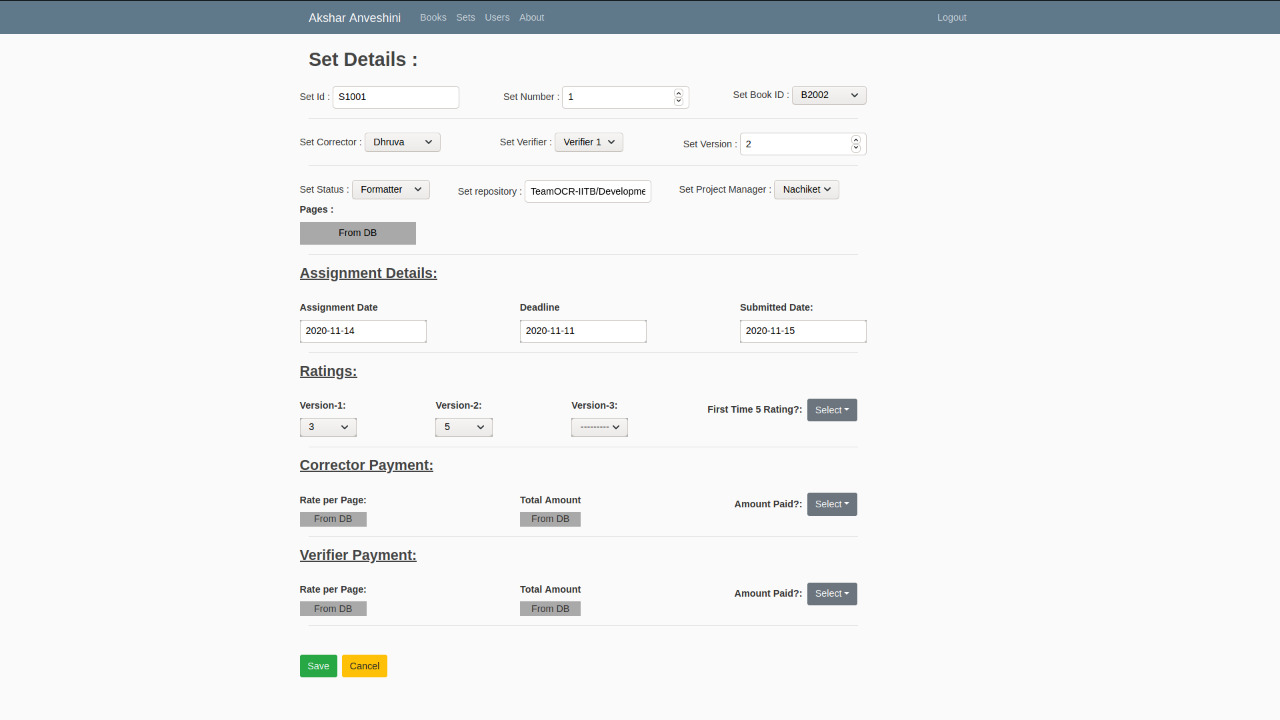
Stage wise output Tracker
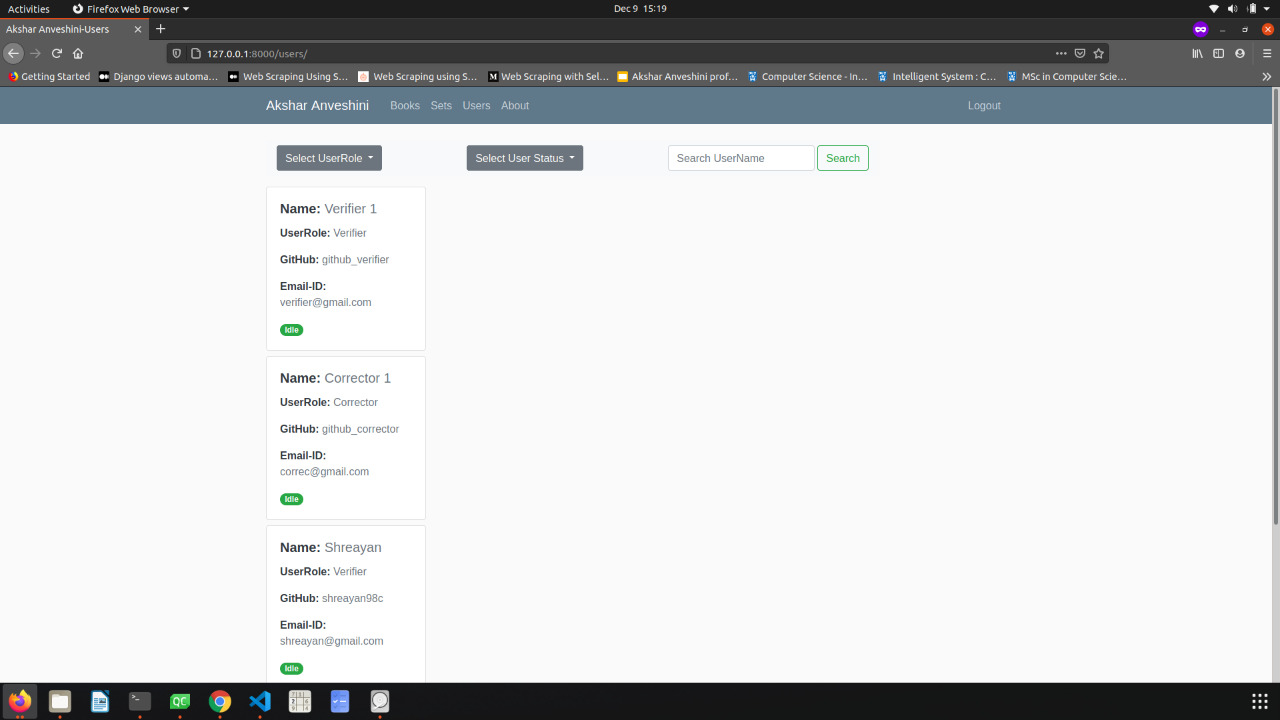
Akshar Anveshini
Optical Character Recognition (OCR) and Post-editing system for the Sanskrit language.
Optical Character Recognition (OCR) is the process of converting the document images into an editable electronic format. This has many advantages like data compression, enabling search or edit options in the images/text, and creating the database for other applications like Machine Translation, Speech Recognition, and enhancing dictionaries and language models. OCR in Indian Languages is quite challenging due to richness in inflections. So, we started with the problem of developing "OpenOCRCorrect", an end-to-end framework for Error Detection and Corrections in Indic-OCR. Our models outperform state-of-the-art results in Error Detection in Indic-OCR for six Indic languages with varied inflections. Even after a good accuracy in OCR, the detected text needs a lot of improvement. Further, in the digitization process of such texts, the second step would be spelling correction and formatting of the text detected by the OCR models. Hence, the end goal is to convert the generated OCR text in accordance with the scanned images of the 10000 books. This will also help us preserve the rich Sanskrit Artifacts and Reference Materials for future uses so that it can be referenced in the future.
Our Motivation
Sanskrit is an ancient language and a proud part of our Indian heritage. It has been passed down the generations, first verbally and later in printed format. As we witness an era of immense technological advances it is our duty to ensure that we carry forward our treasure trove of knowledge, encoded in sanskrit books into the digital era. This motivated us to undertake the task of digitization of our rich sanskrit literature in the form of the Akshar Anveshini project. With this endeavour we aim to translate several thousands of old sanskrit books on various topics like mathematics and astronomy, to a digital format. We wish to make these books easily accessible and discoverable to a greater amount of people than a physical print format allows for and make sure that a proud part of our culture stands the test of time.
Parinamika OCR
The inhouse OCR(Optical Character Recognition) model for the digitization of Sanskrit books.
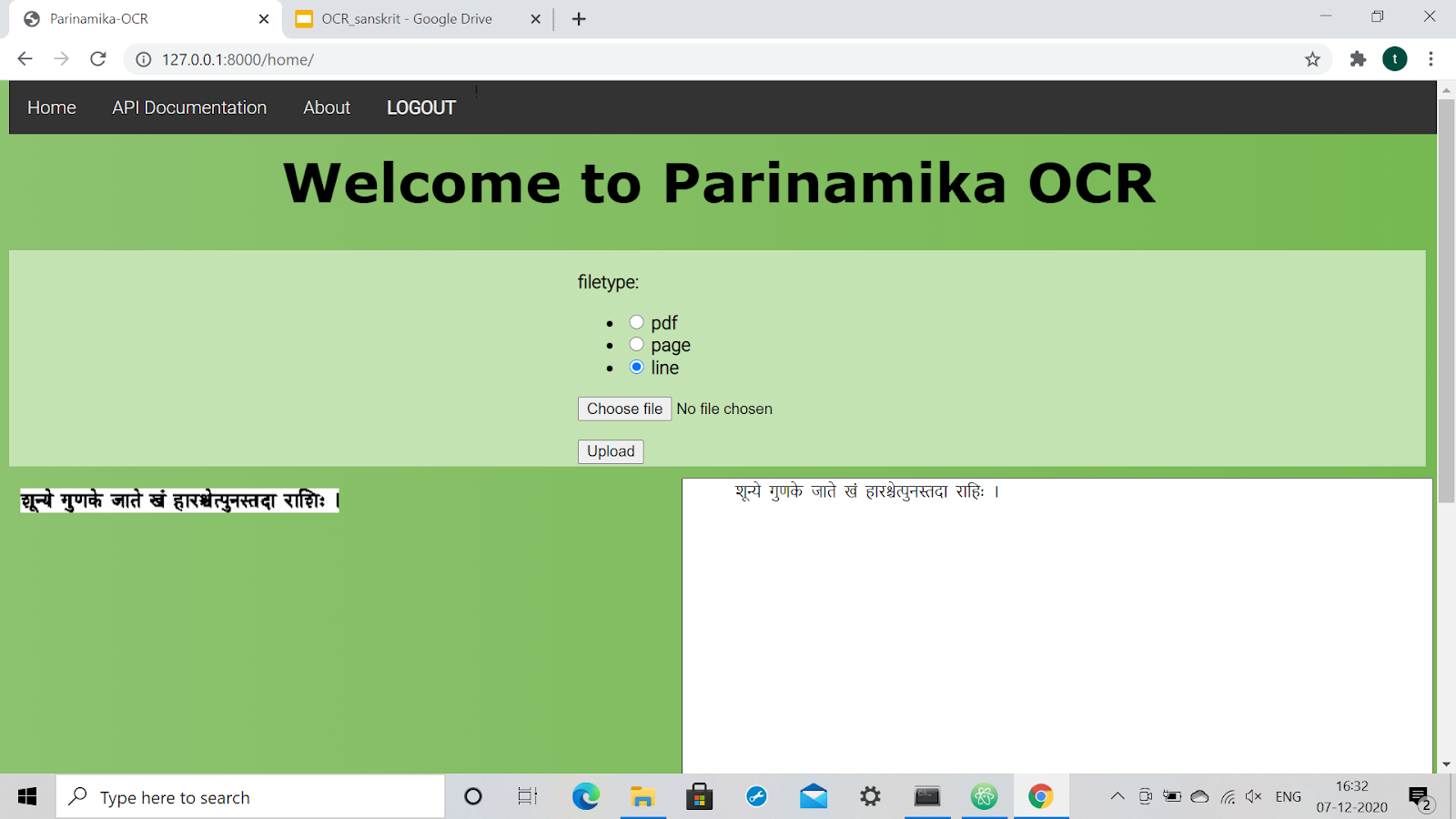
The Parinamika OCR system provides the following options to get the OCRed output of any document:
1. PDF documents
2. Page Images (jpeg, png)
3. Line Images
It uses state of the art technology that gives us 95.14% character level accuracy for Sanskrit text.
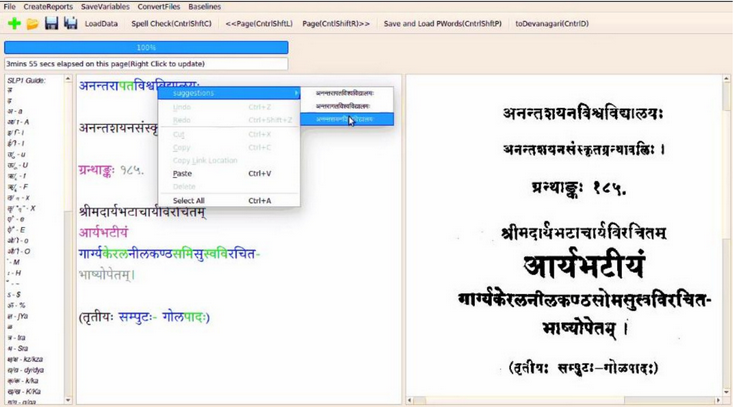
OpenOCRCorrect
End-to-end framework for Error Detection and Corrections in Indic-OCR. Provides suggestions for words that probably have mistakes during the OCR method, hence any mistakes during the OCR process can be corrected by the user.
Installation Guide Linux Installation Guide Windows
Detailed Process Flow More Information
Credentials to use the software can be provided upon acknowledgement/request.
Demo Video:
Publications
Publications related to the projects.
-
GLISTER: Generalization based Data Subset Selection for Efficient and Robust Learning [source code]
In Proceedings of The 35th AAAI Conference on Artificial Intelligence (AAAI 2021).
-
Sub-word Embeddings for OCR Corrections in highly Fusional Indic Languages [source code, video of demo system]
In Proceedings of The 15th International Conference on Document Analysis and Recognition (ICDAR 2019), Sydney, Australia.
-
OCR On-the-Go: Robust End-to-end Systems for Reading License Plates and Street Signs [source code, video of demo system]
In Proceedings of The 15th International Conference on Document Analysis and Recognition (ICDAR 2019), Sydney, Australia.
-
StreetOCRCorrect: An Interactive Framework forOCR Corrections in Chaotic Indian Street Videos [source code, video of demo system]
In Proceedings of The 2nd International Workshop on Open Services and Tools for Document Analysis, associated with the 15th International Conference on Document Analysis and Recognition (ICDAR-OST 2019), Sydney, Australia.
-
Learning From Less Data: Diversified Subset Selection and Active Learning in Image Classification Tasks
Accepted paper at the 7th IEEE Winter Conference on Applications of Computer Vision (WACV), 2019, Hawaii, USA.
-
Error Detection and Corrections in Indic OCR using LSTMs
International Conference on Document Analysis and Recognition (ICDAR) 2017, Kyoto, Japan.
-
A Framework for Document Specific Error Detection and Corrections in Indic OCR
1st International Workshop on Open Services and Tools for Document Analysis (ICDAR- OST) 2017, Kyoto, Japan.
-
Improving the learnability of classifiers for Sanskrit OCR corrections
Proceedings of the 17th World Sanskrit Conference, Vancouver, 2018.
-
A Framework for Error Detection and Corrections in Sanskrit
Research and Innovation Symposium in Computing (RISC) 2017 (Most Admiring Poster Presentation Award), IIT-Bombay, India.
-
Summarizing Multi-Document Topic Hierarchies using Submodular Mixtures
In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), Beijing, China, July - 2015