CATALIST - Camera Transformations for Multi-Lingual Scene Text Recognition
Abstract
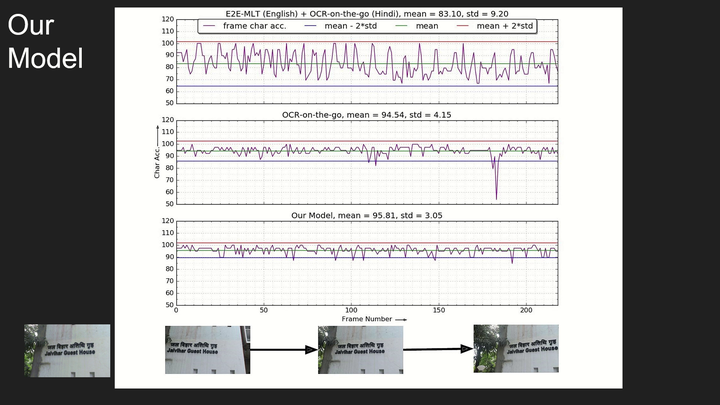
Automatic text recognition in videos is challenging because ofproblems like motion blur, variations in text size, fonts, and use ofvarious languages. Movement of the capturing camera and resultingorientation of text makes the recognition task even more difficult. Attention-based methods have delivered excellent results for scenetext OCR in images. However, they suffer from the problem of attention masks becoming unstable and wandering in the scene. In order to alleviate this issue, we offer a video dataset which contains scene-text videos along with the camera movements. These videos mainly contains sign boards and number plates. We also provide word-level masks for each video frame. The videos are shot both in indoor and outdoor environments.