







RISC 2025
Research and Innovation
Symposium in Computing
22nd - 23rd March 2025
IIT Bombay, Mumbai, India
About
The Department of Computer Science and Engineering at IIT Bombay it thrilled to announce the upcoming RISC 2025, a two-day research symposium scheduled from March 22nd to 23rd, 2025. This event serves as a platform, highlighting the cutting-edge research emanating from the CSE Department.
RISC 2025 will have insightful talks presented by distinguished researchers across three different tracks: Computer Systems, AI/ML, and Theoretical Computer Science. Beyond these engaging presentations, the department will also host interactive sessions, including a poster presentation session showcasing the outstanding research work undertaken by CSE students at IIT Bombay.
RISC 2025 provides an excellent opportunity for participants to delve into the latest advancements in Computer Science Research. Simultaneously, attendees will gain valuable insights into the vibrant research culture flourishing within the CSE Department at IIT Bombay.
Highlights

Invited Speaker & CSE Faculty Talks
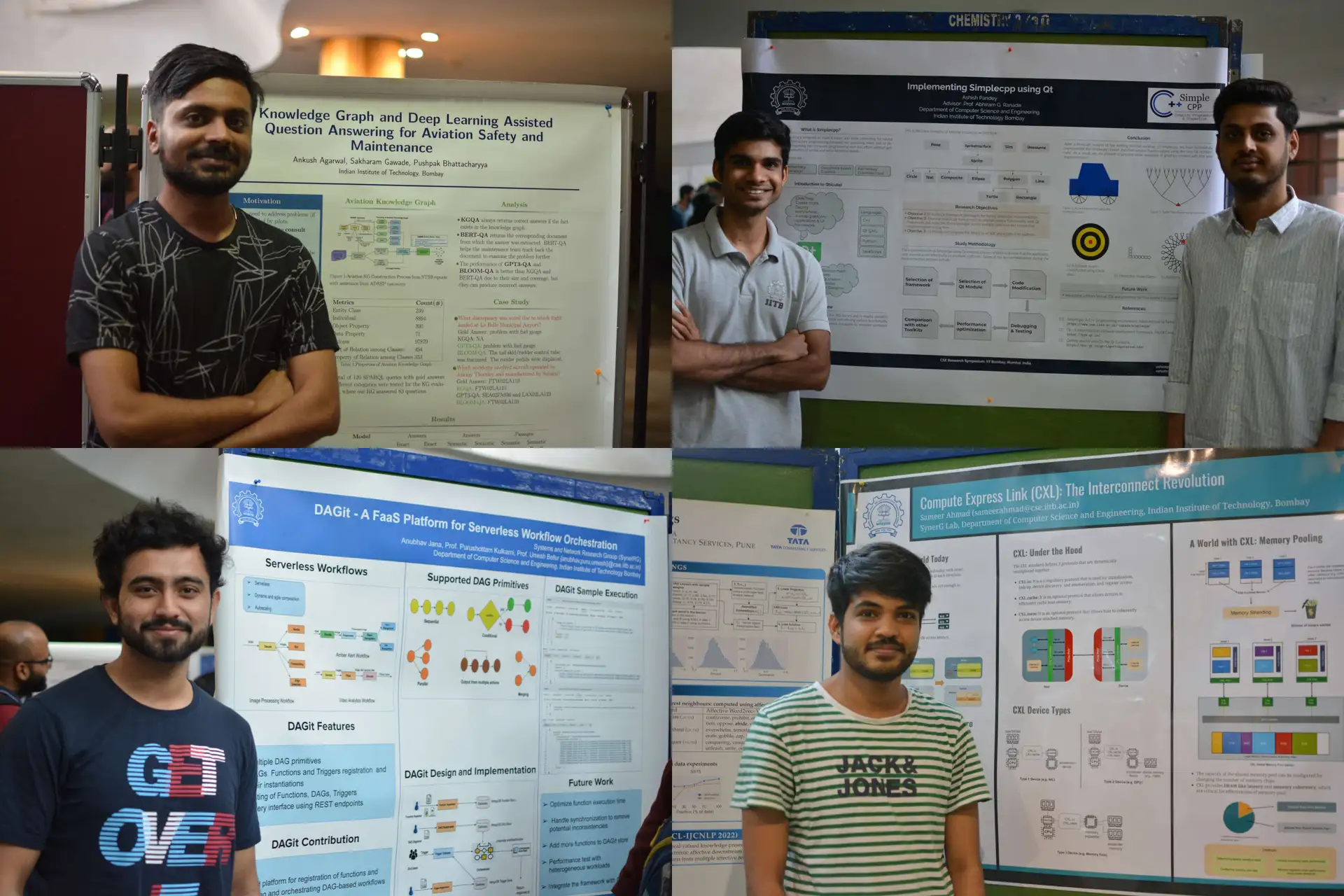
Poster Presentation by IIT Bombay CSE Students

Research Talks by IIT Bombay CSE Students
Keynote Speakers



Faculty Speakers



Panelists



Venue
F.C. Kohli Auditorium,
IIT Bombay, Powai, Mumbai
Schedule
Day 1 (Saturday)
- Attendance of RISC 2025 Participants
- Distribution of Participant Kits
HoD addresses participants and guests about RISC 2025 event and gives overview of Computer Science and Engineering in IIT Bombay
Planar Graphs in Real Life - The Problem of Land Records
Abstract: We look at the problem of Land Records for farm lands - maintaining an accurate match between actual land use and its record of ownership. For the first, there is now an option to time-consuming land surveys - viz. segmentation of satellite or drone images. For the second, we must look at how the government maintains land records, which is as a number of land parcels or polygons in imaginary space in GIS. The question of matching the two then becomes polygon fitting to segmented data. We look at theoretical, algorithmic and practical problems which arise in this process and describe our solutions. This work is part of a project with Govt. of Maharashtra and uses past independent collaboration with Google Research.
Speaker: Prof. Milind Sohoni
Beyond In-Context Learning: Rethinking Few-Shot Adaptation for Structured Tasks
Abstract: Many applications require few-shot adaptation for structured prediction tasks, such as semantic parsing for custom APIs, translation involving low-resource languages, and Text-to-SQL for private databases. These can be framed as structured sequence-to-sequence problems. While In-Context Learning (ICL) is the dominant approach for adapting large language models (LLMs) to new tasks, we show that it has fundamental limitations in this setting. Through a mechanistic analysis with synthetic formal languages, we attribute the failure to difficulty of in-context learning input-output alignments in structured tasks. For light-weight adaptation on such tasks, we will discuss alternative strategies, including case-based reasoning on trees, in-context fine-tuning, paired decomposition of input-output sequences, and grammar-constrained decoding.
Speaker: Prof. Sunita Sarawagi
Bio: Sunita Sarawagi researches in the fields of databases, machine learning, and applied NLP. She is Institute Chair Professor in the Computer Science Department and was the founding head of the Center for AI at IIT Bombay. She got her PhD in databases from the University of California at Berkeley and a bachelor’s degree from IIT Kharagpur. She has also worked at Google Research, CMU, and IBM Almaden Research Center. She is an ACM fellow, was awarded the Infosys Prize in 2019 for Engineering and Computer Science, and the distinguished Alumnus award from IIT Kharagpur. She has several publications including notable paper awards at ACM SIGMOD, ICDM, and NeuRIPS conferences.
Room No: CC-101
| Speaker | Talk Title |
|---|---|
| Vedant Kalbande | Intelligent Caching for Datacenter Applications |
| Samipa Samanta | Dynahints: Silent Threshold Signature for Dynamic Setting |
| Narjis Asad | BIStereo: Using NLI to Detect Skin Complexion Biases in LMs |
| Abhik Bose | P4 programmable data plane for complex applications |
| Omkar Vijaykumar Tuppe | Verification of Transactional Programs under Serializability |
Room No: CC-103
| Speaker | Talk Title |
|---|---|
| Aditya Anand | Program Analysis for Managed Runtimes in Presence of Dynamic Features |
| Gargi Bakshi | Limiting Disease Spreading in Human Networks |
| Lokesh N | Robust Root Cause Diagnosis using In-Distribution Interventions |
| Santhosh Kumar M | Flyt: Software-defined elastic GPU endpoints |
| Devdan Dey | Online ε-Net for Geometric Objects |
Room No: CC-105
| Speaker | Talk Title |
|---|---|
| Prathamesh Navale | Adaptive Software Prefetching for Recommendation Systems at-scale |
| Himanshi Singh | A Convex Hull approach to a sub-quadratic algorithm for Motzkin Rabin Theorem |
| Sandarbh Yadav | Portfolio Optimisation using Policy Search |
| Heinsamding Thou | Will you choose reliability over low-delay in VoIP calls over poor networks? |
| Soham Joshi | Monotone Submodular Multiway Partition |
Participants will have lunch and engaging discussions with CSE Department folks
Formal Methods: Theory and Practice
Abstract: I will present my research journey in formal methods, with focus on the theory of string transformations. The discussion on string transformation will touch upon diverse topics like logic, automata, algebra, constraints. Finally I will discuss the importance of formal methods in industry, the kind of problems we face in the hardware industry and the need for continuous innovation in this area.
Speaker: Dr. Vrunda Dave
Bio: Vrunda Dave received her PhD from CSE department, IIT Bombay under the guidance of Prof. Krishna S. For her thesis on “Some Fundamental Problems and Applications of Word Transformations”, she received Honorable Mention for ACM India Doctoral Dissertation Award’22, and an Excellence for Ph.D Research award from CSE Department, IIT Bombay. She was also a finalist for the E. W. Beth Outstanding Dissertation Prize’22. She works as an Architectural Formal Verification Engineer at Intel.
A Journey to the Post-Quantum-Cryptography
Abstract: Quantum computers are here. While there are ongoing debates on to what extent it is going to replace our good old classical computers, there is no doubt about the fact that our security will surely go for a toss. This is due to Shor’s algorithm and its successors, which can solve the prime factorization and discrete log problems efficiently — two problems that define modern cryptography. Given this fact, the world is rapidly moving towards “Post-Quantum-Cryptography” (PQC), which can withstand quantum attacks. This talk will give a (extremely informal) introduction to Lattice-Based Cryptography, which is going to run on all of your devices in the next few years.
Speaker: Prof. Sayandeep Saha
Panel Topic: Shaping Tomorrow’s Workforce
Panelists:
- Mr. Aman Goel
- Dr. Nagarajan Natarajan
- Dr. Priyanka Naik
- Prof. Shivaram Kalyanakrishnan
- Dr. Vineet Nair
- Dr. Vrunda Dave
Panel Moderator: Prof. Varsha Apte (HoD, Department of Computer Science and Engineering)
CSE Students will present their ongoing research work through Posters, with refreshing tea and snacks for everyone
Day 2 (Sunday)
Robust Customization of Large Language Models
Abstract: Pretrained large language models are increasingly achieving impressive zero-shot accuracies on challenging benchmarks. At the same time, customizing these models to perform well in specific settings is still crucial, e.g. fine-tuning models on private codebases or aligning models to application-specific requirements. In this talk, I’ll present an overview of the area of customizing LLMs that spans prompt engineering, fine-tuning, as well as post-training alignment. In particular, I’ll cover some of our recent ML work on training and aligning models to promote out-of-distribution generalization and robustness to noise in the training data.
Speaker: Dr. Nagarajan Natarajan
Bio: I am a Principal Researcher at Microsoft Research India. Over the last several years at MSR India, I’ve worked on a broad slate of machine learning problems at the intersection of AI and software engineering, AI and systems, as well as in learning theory and optimization. My current interests are largely shaped by the big challenges we face today as we increasingly deploy black-box Large Language Models in real systems like Co-pilots. I’ve collaborated with several researchers, scholars, and students who have shaped my thinking over the years. I owe a lot in particular to Prateek Jain, who mentored me at MSR India in the initial few years, to Prof. Ambuj Tewari who was instrumental in my formative years of research career, and to Prof. Inderjit Dhillon, my PhD advisor at the University of Texas at Austin.
Demystifying System Research
Abstract: System research is the core for building any great product or technology asset. We will explore how to get started on your research journey in systems and career opportunities in this space.
Speaker: Dr. Priyanka Naik
Bio: Priyanka is a Research Scientist at IBM India Research Lab and is part of the GenAI platform team. Priyanka’s prior research explored the space of cloud deployment, networking and observability of microservices such as network functions and extending the same for multi cloud deployments. Prior to joining IBM, she received her Ph.D. from IIT Bombay, India. She is a co-author to a cloud networking book and has also recently been appointed as an ACM Eminent Speaker and looks forward to connecting with institutes to collaborate on tutorials and talks.
Room No: CC-101
| Speaker | Talk Title |
|---|---|
| Mandru Suma Sri | Machine Learning based Attack on Learning with Errors Problem |
| Prateek Garg | From Search to Sampling: Generative Models for Robust Algorithmic Recourse |
| Arhaan Ahmad | Sensitivity Analysis of Decision Trees |
| Anubhav Bhatla | OASIS: Enabling Provably Secure Randomized Caches at Ultra-Low Cost |
| Darshan Prabhu | Spicing Up ASR with LLMs for Low-Resource Languages |
Room No: CC-103
| Speaker | Talk Title |
|---|---|
| Supriya Bhide | Static Single Assignment for Compilers |
| Karthika N J | Leveraging Syntactic and Semantic Unity of Indian Languages for NLP |
| Rahul Kapur | Automated Functional Synthesis: Towards Correct-by-Construction Systems |
| Prerna Priyadarshini | The Other Side of Dynamic Cache Partitioning |
| Prerak Contractor | From Theory to Practice: Developing efficient tools |
Room No: CC-105
| Speaker | Talk Title |
|---|---|
| Saurav Chaudhary | TABuddy: AI-Assisted Grading Tool for Introductory Programming Assignments |
| Krishna N Agaram | Quantum State Preparation with Reinforcement Learning |
| Namrita Varshney | ViKriTi: Glitches in Tree Ensemble Models |
| Abhishek Jagushte | Cache Hierarchy Management for Address Translation |
| Sanjeev Kumar | SrcMix: Mixing of Related Source Languages Benefits Extremely Low-resource Machine Translation |
Security Operations Center : CC-101
Abstract:
Even today, security remains one of the most overlooked aspects of an organization’s infrastructure despite having the potential to cause shock waves across all operations, if compromised.
The high costs of traditional SIEM solutions make facilitating centralized infrastructure security challenging for smaller organizations. As a result, they still resort to distributed solutions such as Firewalls, antivirus, spam-checks, etc. with minimal event correlation between them.
Our entirely FOSS-based Security Operations Center intends to solve this problem.
We demonstrate our use of open-source tools such as Apache Kafka and the ELK Stack to implement the traditional SOC workflow of data ingestion, transformation, analysis and visualization in a resource-light, modifiable and easily distributable way.
Our solution encompasses alerts across multiple domains concerning most organizations. These domains include web, mail, network, applications, hosts and endpoints using a rule-based approach as well as ML solutions for anomaly detection.
BharatGen : CC-103
Demo 1: Developing an Indic Language LLM for Enhanced AI Accessibility
Abstract:
The scarcity of Indic language representation in the digital landscape poses significant challenges in providing equitable access to AI solutions. Despite Hindi and other Indic languages being spoken by millions, they comprise less than 1% of the content available online, while English dominates with over 51.2% of digital content. To address this imbalance, we propose the development of BharatGen, a foundational language model (LLM) designed to enhance Indic language accessibility.
BharatGen has been trained on diverse datasets, with models like Bharatgen-2.6B and Bharatgen-5B (ongoing training) incorporating both English and Hindi datasets, alongside 13 other Indian languages including Assamese, Bengali, Gujarati, and Tamil. The training involved 8.6 trillion tokens, with 3.6 trillion tokens dedicated to Indic languages, ensuring robust multilingual capabilities.
The initiative aims to foster technological sovereignty through data localization, enhance national security and privacy, and promote cultural preservation. By integrating AI into various sectors such as agriculture, healthcare, and education, BharatGen will drive digital inclusion and innovation. Furthermore, public-private partnerships will be leveraged to ensure sustainable AI self-sufficiency. Through BharatGen, we envision a future where AI serves all linguistic communities, preserving cultural identities while driving technological progress in India and beyond.
Demo 2: Speaker-Adaptive Text-to-Speech for Low-Resource Indian Languages
Abstract:
Generating high-quality speech for unknown speakers and low-resource Indian languages remains a challenge in text-to-speech (TTS) systems. We propose a diffusion-based TTS system with a speaker encoder that extracts speaker embeddings from a small audio sample, conditioning a DDPM decoder for multi-speaker synthesis.
Our system initially faced challenges in zero-shot speaker adaptation and duration modeling. To address this, we introduced an attention-based mechanism that extracts duration features from a 2-second mel spectrogram of another audio sample from the same speaker. This improves prosody by aligning speech timing with speaker characteristics.
To enhance zero-shot generation, we employed classifier-free guidance, enabling speech synthesis for unseen speakers while preserving natural prosody. We trained language-specific speaker-conditioned models on the IndicSUPERB dataset for multiple Indian languages, including Bengali, Gujarati, Hindi, Marathi, Malayalam, Punjabi, Tamil, and Telugu.
Our approach improves speaker adaptation and prosody modeling, making Indian language TTS more natural and inclusive.
BodhiTree & EvalPro : CC-105
Abstract:
Grading assignments in introductory programming courses is very common, especially in large classes. To handle this, autograders are widely used. We use our own platform, BodhiTree, an online learning platform that features its own autograder called EvalPro. In our standard grading scenario, we configure input and output test cases, execute the student’s program, and compare the submitted code’s output with the expected results.
Our platform also provides a rubric-based grading interface for non-compiling code, recognizing that students often make small mistakes in an educational setting. This interface allows graders to evaluate such submissions effortlessly with a single click, and the total marks are calculated automatically. To save time, we introduce an AI-powered autograder, TA-Buddy, which utilizes rubrics to suggest relevant ratings for each criterion. A dedicated team of AI enthusiasts works continuously to improve the model, ensuring that the suggested grades align closely with human evaluations, thereby speeding up the grading process.
Our code editor supports single-file, multiple-file, and advanced configurations that allow restrictions on file names and types. It also includes features like running code without submission and uploading code files.
Exams are an essential part of assessment in education, and our platform makes the entire process smooth and hassle-free. Hosting exams is effortless with our system, allowing instructors to set up and manage exams with ease. Exam Mode enables instructors to restrict exam access based on specific IP ranges, ensuring that only students with approved IP addresses can participate in lab exams. Additionally, the Proctor Dashboard provides instructors with a live view of student activities and full control over the exam process.
Faq
Pre-final and final-year undergraduate students, as well as master’s students specializing in computer science and related fields can apply to attend this event
Registration for Round 1 applications is now open. Please complete the registration form before December 25th, 2024
Registration is now closed
No, there is no entry fee or ticket cost for this event
Yes, meals will be provided by the organizing committee for all external participants during the symposium
CSE IIT Bombay will be providing accommodation to outstation participants, based on availability
Yes, there will be dedicated networking sessions for attendees to connect with peers, professionals, and speakers
For further questions, feel free to contact us risc@cse.iitb.ac.in