AI/ML@CSE- YOLO: Real Time Object Detection
Gave a talk today in the Machine Learning reading group of CSE@IITB. With this I become the first one to present in this group. What could have been a better choice than something hot off the press from CVPR 2016? YOLO’s claim to fame is that it is the most accurate real-time object detector and is also the fastest object detector in literature today. Hit the PDF button on the top-left of this page and enjoy the slides.
Followup after talk:
I have added a slide towards the end containing the questions (from the session) that could potentially provide further directions for research. I have also explicitly elaborated on the various terms in the multi-part loss function that YOLO uses.
Below are some of the questions (and answers) from the session for quick reference.
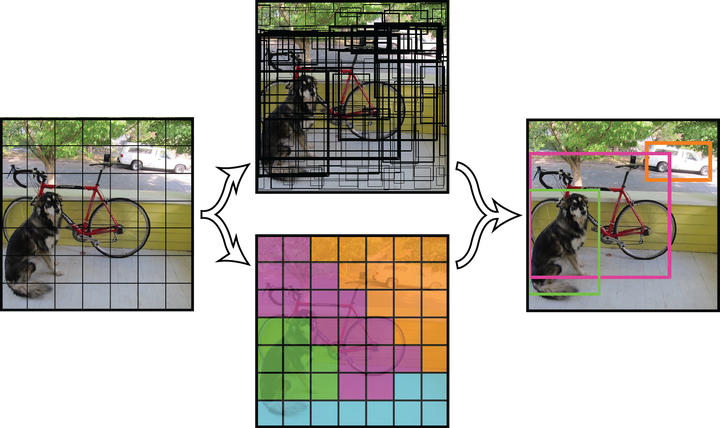
If there is a unique mapping between a grid cell and the object it is center of, do we really need four parameters, x, y, w and h? A: Yes, because given a grid cell, the bounding boxes that it predicts could be anywhere and of any size. x and y marks the center of the bounding box, relative to the grid cell (normalized as an offset between 0 and 1)
How could a prior probably be modeled in the loss function? A: Good question. Included in last slide for further investigation.
Any studies on depth perception in images? A: Good question. Included in last slide for further investigation. This perhaps good give clues for good prior as well!
YOLO claims to generalize well to other domains but has tested itself only for person detection in artworks! Who knows it didn’t do well in other domains? A: Yes, you never know ;)
How is NIN a substitute for inception architecture used by GoogleNet? A: Good question. Included in last slide for further investigation.
Would YOLO do well if in the same object portions of that object are also labelled as the whole? For example, face of the dog labeled as “dog” and the whole body also labeled as “dog” in the same image for the same dog A: It does detect any object appearing in different forms. Plus it does label objects inside objects. Given these two I believe there is no reason YOLO will not do well on the question asked.
Non Max Supression and Thresholding are post-processing steps? A: I am not sure if i answered this as no. I goofed up if I did so. The answer to this question has to be yes, as the output, as we discussed, is a complete tensor with info about all boxes, hence calling for a post processing step (which is quick and doesn’t require any optimization as against the separate optimization required in R-CNN for adjusting the bounding boxes).
YOLO 9000 jointly optimizes classification and detection. Isn’t YOLO doing the same by eliminating that complex pipeline? A: No. YOLO is only bothered about detection and is modeling that as an end-to-end regression problem. The effect of classification is getting implicitly created by the CNN. YOLO 9000 on the other hand has the ability to jointly train on classification data and detection data. Quoting them, “… uses images labelled for detection to learn detection-specific information like bounding box coordinate prediction and objectness as well as how to classify common objects. It uses images with only class labels to expand the number of categories it can detect”.
What is multi-scale training? A: Making a network robust to running on images of different sizes by training this aspect into the model. YOLO 9000 implements this. They argue that since their model only uses convolutional and pooling layers it can be resized on the fly. They change the network every few iterations. Every 10 batches their network randomly chooses a new image dimension size. This technique forces the network to learn to predict well across a variety of input dimensions.
Have they said anything about the choice of S? A: No. They have used S=7 for their experiments but have not commented on how they got that number.
Thought process behind their network architecture? A: Not revealed by them except for the fact that it is inspired by GoogLeNet.