| Jan 2 |
-- |
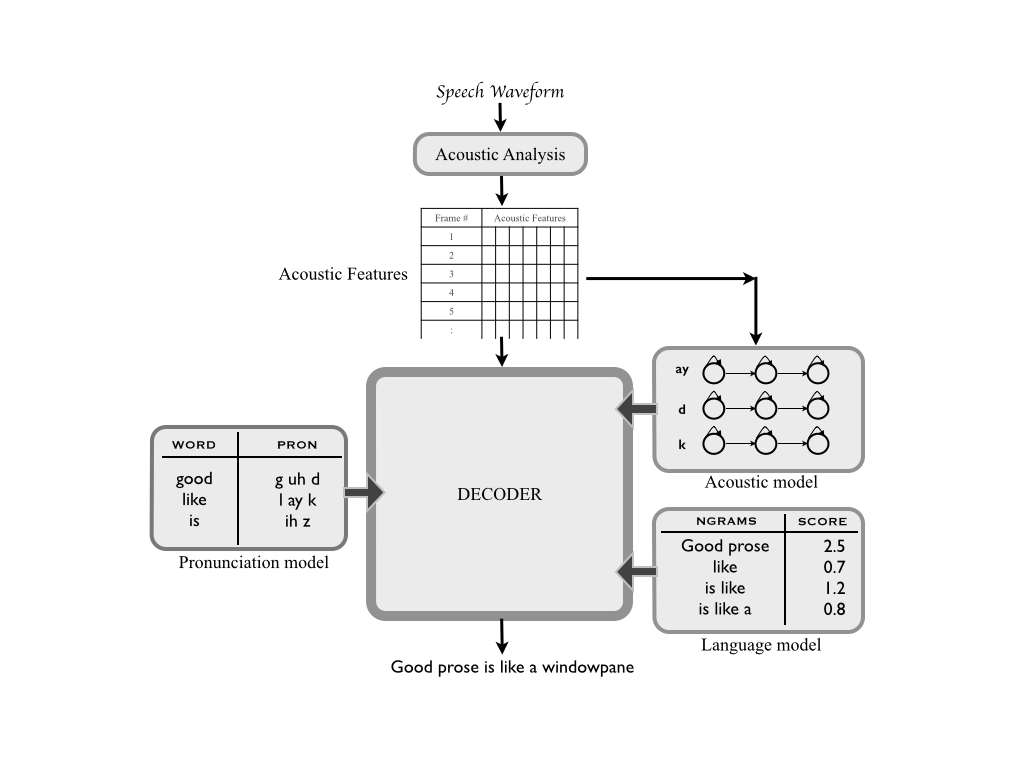
Introduction to Statistical Speech Recognition |
S. Young, Large vocabulary continuous speech recognition: A review, IEEE Signal Processing Magazine, 1996.
If you want a refresher in machine learning basics, go through Part I in the following book: Deep Learning |
| Jan 5 |
pdf/html |
Introduction to WFSTs and WFST algorithms |
M. Mohri, F. Pereira, M. Riley, Speech recognition with weighted finite-state transducers, Springer Handbook of Speech Processing, 559-584, 2008. (Read Sections 2.1-2.3 and 3.)
[Additional reading] M. Mohri, F. Pereira, M. Riley, The Design Principles of a Weighted Finite-State Transducer Library, Theoretical Computer Science, 231(1): 17-32, 2000.
[Additional reading] M. Mohri, Semiring frameworks and algorithms for shortest-distance problems, Journal of Automata, Languages and Combinatorics, 7(3):321-350, 2002.
|
| Jan 9 |
pdf/html |
WFST algorithms continued |
M. Mohri, F. Pereira, M. Riley, Speech recognition with weighted finite-state transducers, Springer Handbook of Speech Processing, 559-584, 2008. (Read Sections 2.4 and 2.5.)
[Additional reading] For pseudocode and more details on determinization/minimization of WFSAs. M. Mohri, Weighted Automata Algorithms, Handbook of weighted automata. Springer Berlin Heidelberg, 2009. 213-254. |
| Jan 12 |
pdf/html |
WFSTs in ASR + Basics of speech production |
M. Mohri, F. Pereira, M. Riley, Weighted Finite-state Transducers in Speech Recognition , Computer Speech and Language, 16(1):69-88, 2002.
[Additional reading] D. Jurafsky, J. H. Martin, "Chapter 7: Phonetics", Speech and Language Processing (2nd edition), 2008.
|
| Jan 16 |
pdf/html |
Hidden Markov Models (Part I) |
(Read Sections I to V.) Lawrence R. Rabiner, A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition, Proceedings of the IEEE, 77(2), 257--286, 1989.
(Required reading) D. Jurafsky, J. H. Martin, "Chapter 9: Hidden Markov Models", Speech and Language Processing, Draft of November 7, 2016.
|
| Jan 19 |
pdf/html |
Hidden Markov Models (Part II) |
(Required reading) Both articles listed against Jan 16.
[Additional reading] A. P. Dempster, N. M. Laird, D. B. Rubin, Maximum Likelihood from Incomplete Data via the EM Algorithm, Journal of the Royal Statistical Society, Vol. 39, 1, 1977.
|
| Jan 23 |
pdf/html |
Hidden Markov Models (Part III) |
(Required reading) Both articles listed against Jan 16.
[Additional reading] J. Bilmes, A gentle tutorial of the EM algorithm and its application to parameter estimation for Gaussian mixture and hidden Markov models., International Computer Science Institute 4.510, 1998.
|
| Jan 30 |
pdf/html |
Hidden Markov Models (Part IV) |
(Required reading) S. J. Young, J. J. Odell, P. C. Woodland, Tree-Based state tying for high accuracy acoustic modelling, Proc. of the workshop of HLT, ACL, 1994.
(Useful reading) J. Zhao, X. Zhang, A. Ganapathiraju, N. Deshmukh, and J. Picone, Tutorial for Decision Tree-Based State Tying For Acoustic Modeling, 1999.
|
| Feb 2 |
pdf/html |
Brief Introduction to Neural Networks |
(Useful reading, chapters 1 and 2)
Michael Nielsen, Neural Networks and Deep Learning, Jan 2017.
[Additional reading]
K. Hornik, M. Stinchcombe, H. White, Multilayer Feedforward Netowrks are Universal Approximators, Neural Networks, 2(5), 359--366, 1989.
|
| Feb 6 |
pdf/html |
Deep Neural Network(DNN)-based Acoustic Models |
(Required reading) G. Hinton, L. Deng, D. Yu, G. E. Dahl, A. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. N. Sainath, and B. Kingsbury, Deep Neural Networks for Acoustic Modeling in Speech Recognition , IEEE Signal Processing Magazine, 29(6):82-97, 2012.
(Useful reading) N. Morgan and H. A. Bourlard An Introduction to Hybrid HMM/Connectionist Continuous Speech Recognition, 1995.
(Useful reading) H. Hermansky, D. Ellis, and S. Sharma, Tandem Connectionist Feature Extraction for Conventional HMM Systems, Proceedings of ICASSP, 2000.
|
| Feb 9 |
pdf/html |
Recurrent Neural Network(RNN) Models for ASR |
(Required reading) A. Graves, N. Jaitly, Towards End-to-end Speech Recognition with Recurrent Neural Networks, Proceedings of ICML, 2014.
(Useful reading) Z. Lipton, J. Berkowitz, C. Elkan, A critical review of recurrent neural networks for sequence learning, arXiv preprint arXiv:1506.00019, 2015.
|
| Feb 13 |
pdf/html |
Acoustic Feature Extraction for ASR |
(Required reading) D. Jurafsky, J. H. Martin, Speech and Language Processing, 1st edition, Section 9.3 Feature extraction: MFCC vectors. (Shared via Moodle.)
|
| Feb 16 |
pdf/html |
Assignment 1 discussion + revision lecture |
--
|
| Feb 20, 23 |
-- |
Midsem week |
--
|
| Feb 27 |
pdf/html |
Language modeling (Part I) |
(Required reading) D. Jurafsky, J. H. Martin, "Chapter 4: Language Modeling with N-grams", Speech and Language Processing, Draft of November 7, 2016.
|
| Mar 2 |
pdf/html |
Language modeling (Part II) |
(Required reading)S. F. Chen, J. Goodman, An empirical study of smoothing techniques for language modeling, Computer Speech and Language, 13, pp. 359--394, 1999.
|
| Mar 6 |
pdf |
Guest lecture by Prof. Shivaram Kalyanakrishnan: Modeling Dialogue Management as a POMDP |
(Useful reading, sections 1 and 2) S. Kalyanakrishnan, Reinforcement learning.
(Useful reading)N. Roy, J. Pineau, S. Thrun, Spoken Dialogue Management using probabilistic reasoning, Proc. of ACL, 2000.
|
| Mar 10 |
pdf |
Guest lecture by Prof. Arjun Jain: Babysitting the learning process for CNNs |
--
|
| Mar 16 |
pdf/html |
Language modeling (Part III) |
(Required reading) H.Schwenk, Continuous space language models, Computer Speech and Language, 21(3), 492--518, 2007.
|
| Mar 20 |
pdf/html |
Language modeling (Part IV) and Introduction to Kaldi |
(Required reading) T. Mikolov et al. Recurrent neural network language model, Proc. of Interspeech, 2010.
[Additional reading] R. Jozefowicz, O. Vinyals, M. Schuster, N. Shazeer, Y. Wu Exploring the limits of language modeling, arXiv:1602.02410v2, 2016.
|
| Mar 24 |
pdf/html |
Search and decoding |
(Required reading) D. Jurafsky, J. H. Martin, Speech and Language Processing, 1st edition, Chapter 10. (Shared via Moodle.)
|
| Mar 27 |
pdf/html |
Search, decoding and lattices |
(Required reading) D. Jurafsky, J. H. Martin, Speech and Language Processing, 1st edition, Chapter 10. (Shared via Moodle.)
[Additional reading] L. Mangu, E. Brill and A. Stolcke Finding consensus in speech recognition: word error minimization and other applications of confusion networks, Computer Speech and Language, 14:4, 373-400, 2000.
|
| Mar 30 |
pdf/html |
Discriminative training for HMMs |
(Required reading, Sections 1,2,3.2,5) K. Vertanen, An overview of Discriminative Training for Speech Recognition
|
| Apr 6 |
pdf/html |
End-to-end ASR Systems |
(Useful reading) A. Graves and N. Jaitley, Towards End-to-end Speech Recognition with Recurrent Neural Networks, NIPS, 2014.
(Useful reading)A. Maas, Z. Xie, D. Jurafksy, A. Ng Lexicon-Free Conversational Speech Recognition with Neural Networks, NAACL, 2015.
(Useful reading)W. Chan, N. Jaitly, Q. Le, O. Vinyals Listen, Attend and Spell: A neural network for LVCSR, ICASSP, 2016.
|
| Apr 10 |
pdf/html |
Speaker adaptation and Pronunciation modeling |
(Required reading) P. C. Woodland Speaker Adaptation for Continuous Density HMMs: A Review, ITRW on Adaptation methods for speech recognition, 2001.
|